How we created a hybrid architecture using AWS Glue and AWS Step Functions to process millions of updates on hotel information
Imagine you go to your hotel for check-in and they say that your dog is not allowed even though the website clearly states that it is!
trivago gets information about millions of accommodations from hundreds of partners and they keep on updating. There are many differences not just in the data format, but also in the data itself. There can be many discrepancies in the information and consolidating them can be a very complex process. But it’s our responsibility to provide the most accurate information to the best of our knowledge.
We usually get around one million updates about meta information of hotels per day, and this can even become several million at peaks. These include information changes (such as they don’t allow pets anymore) and status changes (such as a hotel is temporarily closed for renovation). One of the biggest challenges we face when processing this big amount of data is that it’s computationally expensive.
In this article, we’re going to share how we created ETL (Extract Transform and Load) pipelines on AWS (Amazon Web Services) to process all these information changes and consolidate them.
Problem Definition
We cannot react to these individual updates in real time because we have to check our existing data for each of the updates and it will cause a huge overhead. Moreover, there can be multiple updates to the same accommodation in the updates we get within a shorter time frame. Hence, we should batch the changes in order to get the latest information and also to reduce computational overhead.
We also need to introduce new models to do the consolidation to the pipeline easily, with the capability of testing them separately and individually. We also work closely with a set of Data Analysts who help us to create new models for different attributes to improve the consolidation process. They also need sandbox environments where they can simply plug in models and test them.
For example, imagine that one partner sends an update for the address of a hotel. However, we cannot simply go ahead and use that address as the new address. We have to consider numerous things including what other partners have provided, the location details (i.e. address, latitude and longitude), etc. When we get millions of updates like these, things can get a little bit complicated.
Initially, we had two proposals for the technologies we could use. We picked AWS Glue because it can process a huge amount of data. AWS Glue is a fully managed ETL service provided by AWS that uses Apache Spark clusters underneath, which seemed perfect to process the large number of updates. We also picked AWS Step Functions because it provides more flexibility in plugging new models. AWS Step Functions is a tool to orchestrate different AWS services, which is ideal to accomplish the flexibility we require. To see which service suits us the best, our team divided into two and started developing two prototypes using each of those technologies.
However, at the end of the prototyping phase, we realized that these two technologies have both benefits and drawbacks for our use-case. Even though AWS Glue is good for handling massive amounts of data, it’s not meant for implementing complex business logic. We create models with differing consolidation logic for different attributes (i.e. name, address, facilities and amenities) of an accommodation with the help of Data Analysts and it can get sophisticated if we try to add the capability for adding/removing models or testing multiple models. Moreover, when we presented our prototypes to AWS Solution Architects, they advised us to avoid adding complex business logic inside AWS Glue Jobs.
AWS Step Functions would enable us to plug-n-play models easily. Data Analysts can develop their models independently and we could plug it into the Step Function as a node. But unfortunately, they’re not made to handle a large amount of data at once.
Among these drawbacks, we realized that they’re complementary to achieve our goal. If we could thrive from the advantages of each of the technologies, we could eventually achieve our goal to implement our use-case: “Consolidate different attributes of Hotels/Accommodations upon millions of updates”.
Then we decided to go forward with the best of both worlds: a hybrid solution using both AWS Glue and AWS Step Functions.
The Hybrid Architecture
The final architecture has three main components: Pre-Processor, Task Orchestrator and Post Processor.
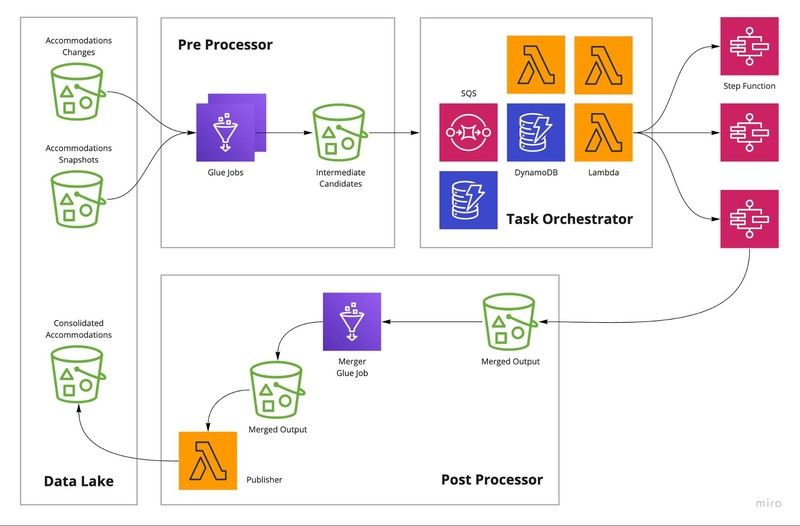
Data Lake
Data Lake is common data storage we have for our department (we call it a domain) where each team writes their output while other teams (both internal and external of the domain) can read from. You can read more about the concept of Data Lakes here.
Pre-Processor
This component consists of several AWS Glue Jobs and it is responsible for picking up the changes from the Data Lake and generating a list of wrapper objects to be processed (consolidated) where each wrapper object contains a list of accommodation objects (candidates) provided by different partners.
[
{
"accommodation_id": 10001,
"candidates": [
{
"metadata": {
"partner_id": "partner_1",
}
"accommodation": {
"name": "My favorite Hotel",
"city": "Isengard"
}
},
{
"metadata": {
"partner_id": "partner_2",
}
"accommodation": {
"name": "Favorite Hotel",
"city": "Ciy of Isengard"
}
},
]
},
]
The “Accommodation Changes” S3 bucket contains all the updates we get in batches and we use the Bookmarks feature of AWS Glue Jobs to extract only the new updates. We extract the IDs of the accommodations and retrieve all the objects corresponding to those. Thanks to the Bookmarks feature, we don’t have to keep track of which files got processed and which weren’t. Since the result of this process can be huge, AWS Step Functions (with Lambda functions) have no capability of processing them. Therefore, we split the result set into smaller Tasks which a Step Function can easily consume (i.e. 1000 accommodations per Task). All these Tasks will be grouped into a unique Consolidation Job ID, which represents a single run of the pipeline.
Sometimes we need to test different or improved consolidation logic in order to determine which delivers more accurate results. Then we create different AWS Step Functions containing different versions of the model(s) and/or several other parameters such as the batch size for the input, output location etc. We call a combination of these parameters a Strategy.
{
"task_candidates_location": "task-candidates-bucket-name",
"step_function_arn": "arn-for-the-step-function",
"consolidated_output_location": "output-bucket-for-consolidated-fields",
"task_size": 1000
}If we have defined multiple Consolidation Strategies, each containing different versions of consolidation models we need to test/use, separate Tasks will be created for each of them.
Task Orchestrator
The responsibility of this component is to, as you guessed, orchestrate the Tasks. When the Pre-Processor creates Tasks, this component will pick them up using an AWS SQS and trigger the corresponding Step Function. And it keeps track of the active Consolidation Units (AWS Step Functions) running to do the load balancing of different models.
{
"consolidation_job_id": "2d1bba27-63e4-423a-931c-0fa5e7fc678f",
"total": 15020
"succeeded": 10293,
"failed": 0,
"status": "PENDING"
}
Triggering the Post Processor for a completed Consolidation Job is also a responsibility of the Task Orchestrator when the number of processed Tasks is equal to the number of received Tasks.
Consolidation Units
A Consolidation Unit is implemented using AWS Step Functions. It has multiple State nodes, each responsible for consolidating one or several inter-dependent fields.
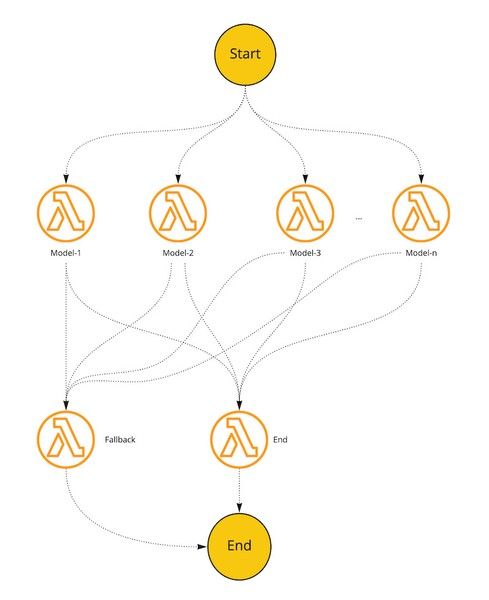
One of the best things about using a Step Function as the Consolidation Unit is the ability to add more states for a particular model without affecting the others. And this model can be an AWS Lambda function or even an internal or an external endpoint. Hence, if we need to plug in more sophisticated consolidation logic, such as Machine Learning Inferencing, we can easily use an Amazon SageMaker endpoint and then the logic will reside completely outside of the Step Function.
However, due to the restriction on the maximum result/input size exchanged between states (which is 32,768 characters), we cannot pass the consolidated results in between the states inside the Step Function. Because of this, we pass the output location to each model and it writes its output to the corresponding prefix in the output S3 Bucket. Each output follows a similar format (schema) so that the Merger Glue Job in the Post Processor can easily merge the results.
After processing the given Task, each model returns several statistics to the End node including the duration, number of consolidated accommodations, models version used, etc. These statistics will be stored on a DynamoDB table per Task and will be used to determine if a given Consolidation Job is completed. On failure, the Fallback state is triggered and the failure will be reflected on the aforementioned table.
When all or a certain percentage of Tasks for a certain Job ID is successful, the Merger Glue Job is triggered for that particular Job.
Post Processor
The Merger Glue Job picks up all the consolidated outputs corresponding to the provided Consolidation Job ID from the Merged Output S3 Bucket and merges them for each accommodation. The merged accommodations will be written to another internal bucket and a Publisher lambda function will pick them up to transform them into the agreed-upon schema, then write back to the Data Lake.
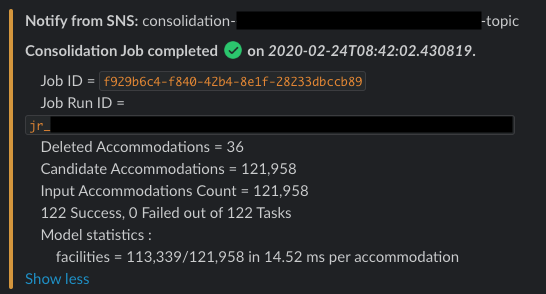
When the Merger Glue Job finishes, it will be reflected on the Task Orchestrator to make the Consolidation Job as either Succeeded or Failed. At this point, it will send a Slack notification to the team Slack Channel.
Challenges
Orchestrating AWS Glue Jobs
In the Pre-Processor, we have several Glue Jobs and one should be triggered after the other. But most importantly, one should pass values to the other. For instance, the first Glue Job detects the changed accommodations and it generates a Consolidation Job ID for the run, then the next Glue Job should know this ID to retrieve the changed (keys of the) objects.
For this purpose, we’re using AWS Glue Workflows, which is an orchestration service for AWS Glue related services such as Glue Jobs and Crawlers.
There are two main issues we found with AWS Glue Workflows so far.
The libraries on the clusters (behind AWS Glue) have an older version of Boto3 (Python SDK for AWS) which doesn’t support AWS Glue Workflows. So we had to sideload the latest Boto3 libraries as a third-party dependency.
AWS Cloudformation Templates do not support AWS Glue Workflows yet. The only way we can define a workflow is by using the web console. Because of this, we can’t track the workflows using version control (such as Git), and we have to manually create them whenever we need them.
There are some other limitations such as not being able to pass parameters when triggering a workflow, but those can be solved programmatically.
However, AWS Step Functions can also be used to orchestrate AWS Glue Jobs, but we haven’t investigated much on it.
Unpredictable workload on the Workers in Glue
AWS Glue uses Apache Spark under the hood and you can either use Scala or Python to write your code. However, you need to understand how Spark works when you write your code to make it more efficient. Otherwise, the Worker nodes in your Glue Job will run out of memory if they get more load than they anticipate. You can always increase the CPU and memory (by increasing the WorkerType and/or NumberOfWorkers in the Glue Job), but that’s merely the solution to the problem, and will cause more costs! If you need to optimize your Glue Job, you need to understand how the data will be distributed among the nodes.
For example, imagine you need to load data from two S3 Buckets into separate DataFrames, run a Spark join on them and write the output to another S3 Bucket. In this case, each worker will only have parts of each of the two DataFrames. However, if data chunks (rows) you want to join are on different workers, it will introduce a huge overhead in transferring them in between the workers.
One way to evenly distribute the data among the worker nodes is to repartition the data based on the keys (fields) you’re going to do the join on before doing the join.
One other way of improving the performance of your Glue Job is to explicitly delete the DataFrames from memory when you’re done using them. You can use inbuilt operations on the programming language such as the delete keyword, however, it’s recommended to use the unpersist() method on the DataFrame.
Passing results between AWS Step Function States
In an ideal world, the models shouldn’t know about where to get the data and where they should write the output. However, it’s not possible when you have the limitation on the input and the output size. There is a quota enforced by AWS itself to limit the input and result size between States (in an AWS Step Function) to 32,768 characters (32 KB). Due to this limitation, we cannot pass bigger objects to the models nor get bigger outputs from them.
One way to overcome this problem is to pass the input and output locations between the states using messages. Instead of passing a whole list of accommodation objects to the Step Function, we pass the S3 location of the Task to the Step Function and the model will read the file from that location. And whenever it produces an output, it will write the results to the given output location and return the location of the file to the next state.
However, we should be careful if the next state wants to access that particular file, since it won’t be immediately visible from the API requests (such as the get_object() method of the boto3 S3 client) because it can take a few seconds for the file to be propagated through the availability zones.
Reading/writing data across accounts
As explained earlier, we store our data in a separate AWS account, which initiated a whole new set of problems related to IAM. In our development account, we have AWS Glue Jobs reading from and Lambda functions writing to this Data Lake account. We should enable cross-account access to the S3 Buckets in the Data Lake account so our components in the development account can interact with them.
For the AWS Glue Jobs, which read data from the Data Lake, we can allow it to read from the Data Lake by adding the read access in the S3 Bucket Policy.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::account_id:role/role-related-to-the-glue-job"
},
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::my-bucket",
"arn:aws:s3:::my-bucket/*"
]
},
...
]
}
We also should make sure the IAM Role related to the Glue Job has permission to read from this bucket in the Data Lake.
If you’re writing to the Data Lake account from either Lambda functions or AWS Glue Jobs, we need to do the same, but with write permissions. However, when we write to an S3 Bucket in a different account, the ownership of the object remains with the writing account. Because of this, the Data Lake account users cannot read or change the file. To solve this, we have to pass the ACL to give ownership of the files to the bucket owner.
If you’re writing from a Lambda function, we should set the ACL parameter to 'bucket-owner-full-control' (or whatever suits you from this list) when calling PutObject API call.
s3_client.put_object(
ACL='bucket-owner-full-control',
Key='my_awesome_file.json',
Bucket=my_bucket_name,
Body=file_content
)However, if you’re writing data from an AWS Glue Job, we don’t have access to the above function call. Then we have to pass this parameter in the Hadoop configuration inside the Glue script.
context: GlueContext(SparkContext.getOrCreate())
context._jsc.hadoopConfiguration().set("fs.s3.canned.acl", "BucketOwnerFullControl")Detecting Glue Job failures
We have configured AWS CloudWatch Alarms for (almost) all the components in our pipeline AWS::CloudWatch::Alarm. However, we couldn’t get them working for AWS Glue Jobs using the metrics mentioned in the documentation.
After some discussion with AWS Support, we figured that we needed to use CloudWatch Events to detect the status of our Glue Jobs. On each stage of an AWS Glue Service (as mentioned here), it will trigger AWS CloudWatch Events and other services can subscribe to them.
We created an AWS Events Rule subscription to detect FAILED states of our Glue Jobs and send those events to an SNS topic, which is sent to our team Slack channel.
MyGlueJobFailEvent:
Type: AWS::Events::Rule
Properties:
Description: This rule is to detect if the MyGlueJob fails
Name: 'name-for-my-event'
EventPattern:
source:
- aws.glue
detail-type:
# Check the available detail types here:
# https://docs.aws.amazon.com/glue/latest/dg/automating-awsglue-with-cloudwatch-events.html
- Glue Job State Change
detail:
jobName:
- !Ref MyGlueJob
state:
- FAILED
State: ENABLED
Targets:
- Arn: 'ARN-of-my-SNS-topic'
Id: 'SomeIDForTheTarget'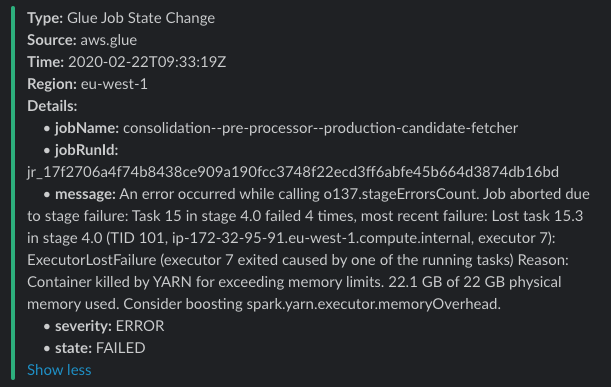
One advantage of this approach is that we can use the same rule to detect different state changes of multiple Glue Jobs.
Conclusion
Handling a large amount of data on the cloud can be very challenging and applying business logic to this data adds even more complexity. We had the challenge to react to millions of updates to accommodations and consolidate the metadata about them.
Instead of aligning towards one technology, we designed a pipeline leveraging the power of AWS Glue and the flexibility of AWS Step Functions. Even though it introduced additional complexity to orchestrate the services, it also allows us to change and monitor different parts of the process independently.

Follow us on