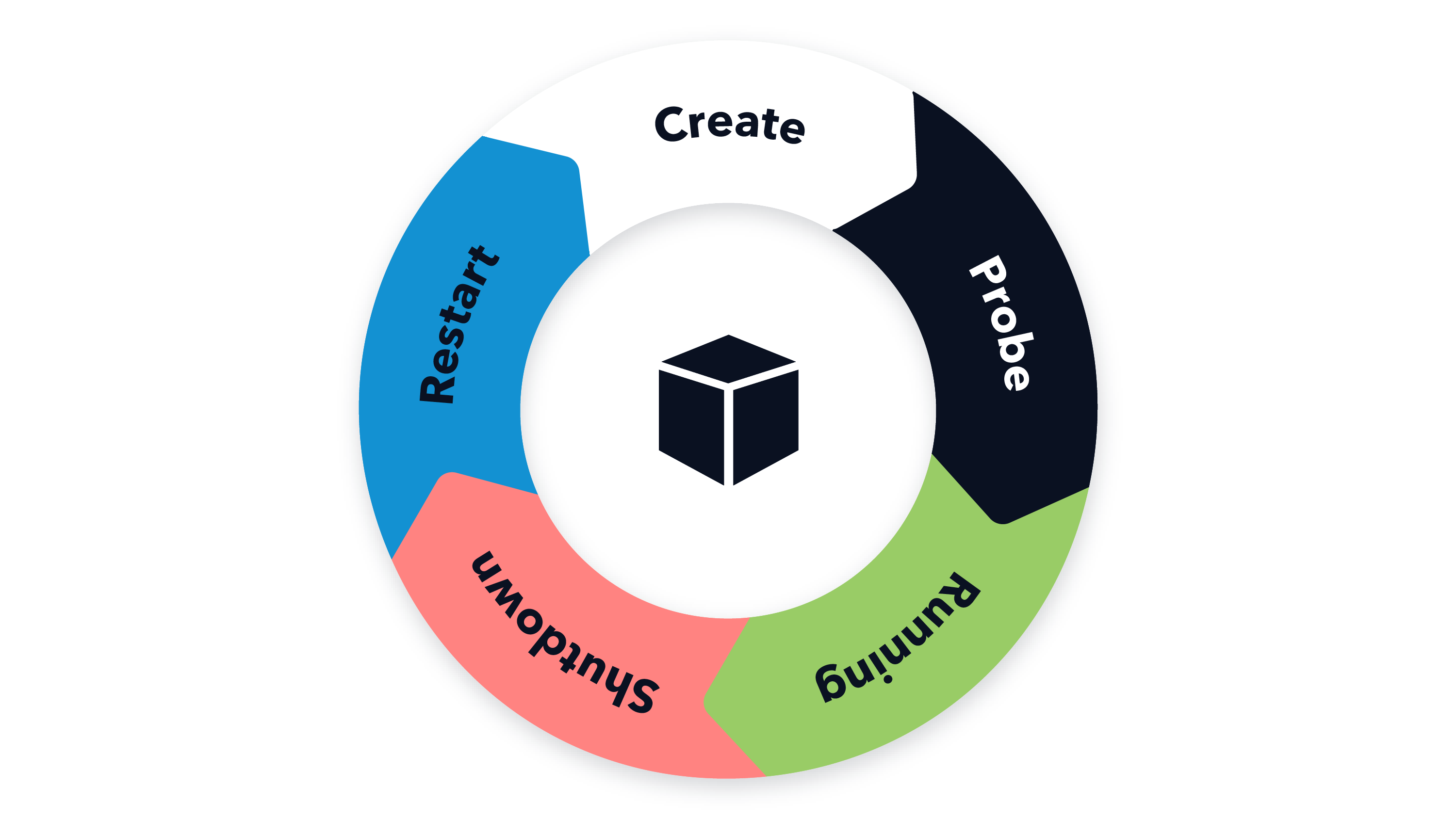
In 2020 we started to migrate one of our most significant workloads, our Node.js based GraphQL API and many of its microservices, from our datacenter to Google Kubernetes Engine. We deploy it in three GCP regions, each having its Kubernetes cluster. Since then, our monitoring infrastructure has changed due to various periods of instability and pandemic induced scaling challenges.




Follow us on