
trivago Intelligence was born in 2013 with two main objectives: First, to provide bidding capability to the advertisers, who are listed on trivago, and second, to provide them with metrics related to their own hotels; like clicks, revenue, and bookings (typical BI data). This project faced a wave of inevitable data growth which lead to a refactoring process which produced a lot of learnings for the team. As I expect it to be useful for other teams who deal with similar challenges, this article will describe why a team started a full migration of technologies, how we did it and the result of it.
The platform was developed with the following stack at that time:
- Monolithic Architecture: Easy to debug and to on-board new talents.
- MySQL (row oriented): The amount of data at the time was not bigger than 150.000 rows, so it was powerful enough.
- PHP: Pretty popular and easy to find talents with experience.
Around 3 years ago, we started facing some performance problems, mostly related to the exponential data growth. In previous years we dealt with it by not allowing custom data ranges, so we could pre-materialize the views using processes behind the scenes. But even with these pre-aggregated tables we had some workflows which took more than 10 hours. The big data apocalypse had only just begun.
This growth completely changed the specifications of our platform, and pushed us to start thinking about how to solve this problem. For a better understanding, we increased the amount of rows managed from 250.000 to 1 billion (1.000.000.000).
Let’s summarize this migration in three main aspects: Data, Architecture and Programming Language.
Data
The main goal was to handle a huge amount of data and make the new implementation last for several years. We invested our time in setting benchmarks of some of the most popular databases that fulfill the following requirements: scalable, column-based, open source, compatible with the Hadoop ecosystem.
Due to the nature of the platform, we decided to move to a column-oriented DBMS, which is more appropriate when you need analytical performance, because it stores the data internally by columns instead of rows (BI-like queries with joins, predicates and aggregations). So taking this into account, we decided to use Kudu as a storage engine. It provides a combination of fast inserts/updates and efficient columnar scans to enable multiple real-time analytic workloads across a single storage layer. However, Kudu doesn’t provide an SQL engine on its own. Since we wanted to keep using SQL as a query language in our application, we decided to implement Impala as an SQL engine, which matches perfectly with Kudu and the whole Hadoop ecosystem. Impala is well-known for its massive parallel processing capabilities, which is great if you need to keep query times low, and that show results in real time.
By implementing this technology we drastically decreased our response time and we are now able to serve views, which took days to load, in real time.
Architecture
Software architecture is critical, because it defines the foundation of your project. It has to handle all the different technologies, the relationship between them and even how a team of developers is organized.
Due to our needs, we decided to move to a microservices architecture, which, put simply, splits the project into small independent pieces of code that share the same business logic. This makes it easy to develop and maintain the project and even works perfectly among teams, allowing them to deliver independently. However, it adds complexity to other areas (as we all know, the complexity doesn’t disappear, it just moves) like communication and the deployment system, among others. To reduce this complexity in certain areas in which we didn’t have it before, we started using gRPC, a full framework of remote procedures calls, that removed all the complexity regarding communication between microservices from our side. On the other hand, we used the Nomad ecosystem to help us with the organization and automation of the deployment of every application in every infrastructure at every scale.
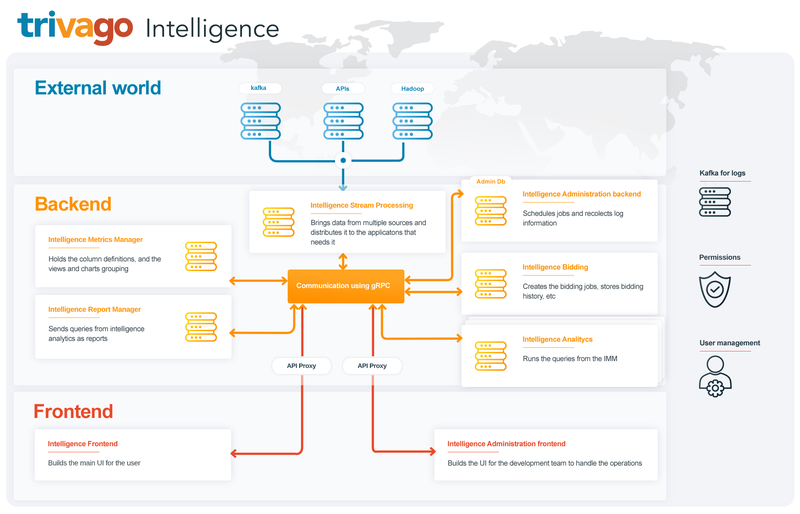
Thanks to this new architecture, we are now able to increase the resources of specific microservices. For instance, we can add resources for the microservices in charge of fetching data, while reducing them for the ones which are not in high demand – like authorization.
Programming Language
Choosing the right programming language is essential. It is the most-used tool for all the developers. In this context, we pondered a lot on keeping or changing PHP as our main language. After analyzing the pros and cons in several meetings, surveys and tests, we decided to switch from PHP, an interpreted language, to a JVM language called Kotlin, which, at that time, was brand new.
Technically speaking, we could say that Kotlin is faster than PHP and offers better support to run processes in parallel. However, this brought up several questions:
Is it really necessary to switch to a new language?
Why should we now start the project from scratch and remove the capability to reuse code? Why should we now start learning a new language, with all the things that this implies (new syntax, new paradigms and even new ways to think)?
The answer is very simple…
Because we love pushing the boundaries of what’s possible! This is the reason why we love to learn new languages. It is the best way to keep the developers hyped. It opens new possibilities and encourages the team to challenge each other and grow, both in knowledge and professionally.
After 2 years of programming, our experience as Kotlin developers could not be better. We love the language. It helps us use complex models like threads in a really easy way. We were able to decrease some processing times from nine hours to 20 minutes. These are some reasons why the popularity of Kotlin among companies increased exponentially, so the recruitment of new talents is getting easier every month. Kotlin 1.2 status
Conclusions
After more than one year running the “new platform” in production, we are more than happy. It gives us infinite of possibilities to cheaply scale the project and fight against the “Big data Apocalypse”.
Of course everything has downsides, especially the microservice architecture which might be a hot trend, but it does not come without some drawbacks:
- Since now everything is decoupled, the tracing of errors is spread over several modules, so we need to use specific tools to help us (e.g. Jaeger).
- In some scenarios we have to write additional code to avoid service disruption and ensure continuous availability.
- Running the project locally is more complex, as we need to coordinate several services working together.
- By increasing the number of remote procedure calls, latency plays an important role.
It wouldn’t be fair if we just mentioned the technical part. It required a heroic management effort to accomplish this full migration of technologies. None of this would have been possible without the effort that went into organizing and coordinating the team.
We are talking about planning huge roadmaps, recognizing possible blockers in advance, as well as motivating and encouraging a team to leave their comfort zone and take a leap into the unknown.
And, last but not least, let’s not forget about the empowerment and motivation that this change brought to a group of developers that now feel more confident to take on new challenges!
Credits
title painting: Benjamin West - “Death on the Pale Horse”, 1796

Follow us on