
At trivago we operate a hybrid infrastructure of both on-premise machines and clusters on Google Cloud. Over time, we came up with a set of deployment guidelines for running our workloads as more and more of them are migrating to Google Cloud. These are not strict rules, but rather suggestions to best serve each team’s needs.
Teams are meant to have full control over their workloads, but most of the time they “just want to run things” and do not have the time or resources to care much about managing the underlying infrastructure. This makes it even more important to carefully consider which level of involvement a team wants or requires.
We noticed that our heuristics could also be useful to others, which is why we decided to share them with the public. Every infrastructure is different, so you might have to adjust those recommendations to your specific requirements.
General considerations
We advise teams to use containers as the “packaging” method for their apps.
The reason is rather simple:
Applications have the tendency to grow, and once they pass a certain point, teams face themselves with a migration as there are better ways to run their applications.
For example: We recently had the case of a VM-hosted application that had been optimised so much, that it was now feasible to run on Kubernetes, removing the need for a custom deployment pipeline.
Now, the most “feature complete”, but albeit not the most simple way of running your applications, is Kubernetes. You have basically all the options here, and that is why we prefer it as the default target for medium to large-size applications.
To run on Kubernetes you need to have your application deployed in a “resource envelope” or “pod”, which currently must be a collection of Docker containers.
As of this, we strongly advise teams to either use Docker containers for production and development, one of both, or at least work in a way similar to containers. In case of VM provisioning for example, you can write things like Packer scripts in a way similar to the way you write Docker files, which will make it easier to migrate to containers later on.
Note: GCP has built-in support for VMs that start a Docker container right after boot.
Simplified decision flow
To make decisions easier for developers, we created a little flow chart to use as a guideline:
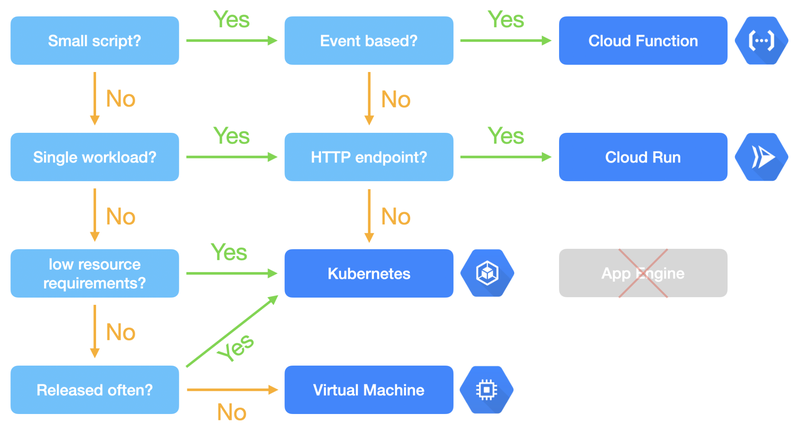
Cloud Functions
Cloud functions are useful for small, single scripts, which react on events e.g. from pub/sub.
A good example is a newsletter script that sends out emails every time a file is uploaded to a Google Cloud Storage bucket.
These events should be infrequent, i.e. there should be times where the script is not running.
In that case you will benefit most from Cloud Function’s ability to “scale to 0”.
For long-running workloads you could benefit from committed use discounts more, which would require the workloads to run on VMs, which includes GKE.
Caveats
- Cloud functions can, as of today, not access anything inside our shared-VPC. Serverless VPC access will probably solve this, but does not do so yet. There are other potential options, but those are cumbersome to manage and set up.
- You should not use Cloud Functions for user-facing HTTP workloads.
Cloud-Run is better suited for this. See below. - Cloud functions are not meant to hold state by themselves. This means any data generated by them has to be stored in managed services like CloudSQL or GCS.
Cloud-Run
Cloud-Run is ideal for small to medium sized user-facing web applications. Think of it as “Kubernetes in easy mode”. A good example is an internal, web-based tool. It can be run from a single container and does not require other services to function. Similar to Cloud Functions, there are also times where nobody is using this tool, i.e. you can benefit from “scale to 0”, too.
Cloud-Run comes in two flavours: fully-managed and self-hosted (GKE).
Caveats
- Fully Managed Cloud-Run can, as of today, not access anything inside the shared-VPC. This is essentially the same issue as with Cloud Functions.
- Fully Managed Cloud-Run can only server requests that last less than 10 minutes. There are workarounds for this though.
- GKE based Cloud-Run requires a bit more initial management overhead, but has full shared-vpc access. It also does not have the 10 minute limitation for request durations.
- Similar to Cloud Functions, Cloud-Run workloads cannot hold state by themselves (no volume mounts). There might be ways around this, but you should keep your state somewhere else.
Virtual Machines
Virtual machines should do the heavy lifting. Workloads that use a lot of resources, have a high uptime or special resource demands – things like databases, huge caches or similar workloads.
Rule of thumb: If a single instance of your workload would eat up more than 1/2 of one of your typical GKE node’s resources, it is probably suited for a VM.
VMs come with a huge additional challenge, which is the deployment pipeline. A good idea is to use so-called “golden images” to avoid surprises during autoscaling or node replacement. But this leads to long build times and slow turnaround times. If you only deploy once a month or even less frequent, this will likely not bother you.
For more frequent deployments we encourage teams to consider Hashicorp’s Nomad, as we’ve had good experiences with it on our bare metal machines. It is relatively easy to set up and allows you to quickly roll out deployments without having to change the underlying VM image.
Caveats
- You need to care about a lot more details like, deployments, dependency management, OSupdates, custom metrics, logs, self-healing, autoscaling, config management, remote access, i.e. everything that the Kubernetes/Docker ecosystem has already solved for you.
App Engine
We advise teams not to use App Engine, but to use Cloud-Run instead. If App Engine is still a requirement for any reason, “App Engine flexible” should be used. This model can, in certain cases, be considered as an alternative to Nomad for managing workloads on VMs.
- App Engine is not available in two of our three main regions (as of Mid-2020). Accessing services in the datacenter or our main region will hence introduce additional costs due to inter-regional network traffic.
- App Engine, especially App Engine standard, is an ecosystem in itself, which can lead to additional effort when you later need to migrate away from it.
- App Engine standard cannot connect to access anything inside our shared-VPC, which is again the same issue as with Cloud Functions.
App Engine flexible is capable of accessing the shared-VPC, but requires a bit more management overhead. - App Engine flexible cannot scale to zero.
- Similar to Cloud Functions or Cloud-Run, App Engine workloads cannot hold persistent state by themselves as volume mounts are ephemeral.
- GKE or Cloud-Run in combination with other managed services can essentially cover all the use-cases of App Engine Flex and is closer to other workloads we run inside trivago, which is why we consider Cloud-Run to be a better option here.
Kubernetes
We advise teams to use Kubernetes for medium to large-size workloads, cron jobs, stream processors or basically anything that does not really fit into the former categories. If you’re familiar with Kubernetes, it is a very good default option for > 90% of your workloads and you have a lot of room to grow if required.
Multi-tenant or single-tenant?
There are multiple options to run Kubernetes. You either create clusters which are shared between teams, or you give each team their own cluster. We decided that it is probably better to have a couple of medium to large-size clusters instead of hundreds of small clusters. There are three reasons for this: costs, subnet resources and management overhead.
With many small clusters you need a lot of people looking after these clusters, or substantially more complex tooling, which requires a lot of people to build and maintain it. Furthermore you pay for every new control plane and for every unused core or GB. These costs can be reduced a lot by using shared clusters.
Last but not least, we’re operating our clusters in a shared-VPC. This means that the number of subnets is limited. GKE clusters tend to consume quite big ranges, which means that having many clusters will make us run out of IP-space very quickly.
The bootstrapping of projects on shared clusters is also quicker for teams. They request a namespace and are good to go, with things like monitoring, VPA, HPA or Istio already in place and configured when needed. Updates to these shared components will be managed centrally, while teams keep full control over their workloads inside their namespaces.
There are a few advantages for small clusters too, but we will come to this in the next section.
We have come up with a set of shared clusters in 3 tiers each, which we call “edge”, “stage” and “prod”. While “prod” should be clear, we treat “stage” as “prod without user traffic” or “next-prod” and “edge” as a kind of playground for teams to test out things in an actual cloud environment.
The clusters are “tools” for internal tooling, “build” for CI/CD related workloads, “dataproc” for stream processors or similar workloads and a couple of project-related clusters. The latter are clusters intended for user-facing products, which are considered “big enough”. The main trivago webpage for example is backed by three clusters, where each has different responsibilities and slightly different requirements.
Guidelines for running single-tenant clusters
As already mentioned before, we encourage teams to enroll for a namespace on the already existing clusters. However, there might be cases where a single-tenant cluster does make sense.
Single clusters can be optimised to a specific use-case a lot easier as you don’t have to align between teams. Replacing the control planes is also a lot simpler for the same reason. If you place these clusters in project-local-VPCs, you also don’t have to worry about running out of IPs, like you do when using a shared-VPC. You could still access services inside the shared-VPC via NAT, if you are fine with one-way communication and a bit of networking overhead.
If teams choose to go this way, there are a couple of rules to follow:
- Single tenant clusters must be managed by at least one dedicated SRE who should be planned as being occupied by this position full time for at least a year.
- Be aware that people get sick or go on vacation, so “one SRE” actually means 1.5 people minimum.
- The team / the assigned SREs are fully responsible for this cluster and must assure a reasonable uptime. Depending on the scope of the product, this also means that an on-call process has to be put in place.
Summary
We hope this little summary will help you to find your own guidelines on workload placement or might help you with current questions on this matter.
Google constantly introduces new services, or adds new options to existing services, that will likely deal with most of the concerns listed in this article. As of this, we will surely challenge and revise these guidelines over the years, so don’t consider them as set in stone.

Follow us on