
What does Data Science at trivago look like in practice? Which major challenges have we encountered as a travel-tech company since the COVID-19 outbreak? What’s it like to work in Data Science at trivago? In this Q&A with James Neaves (Business Intelligence Lead), Andrea Fernandez (Data Science Team Lead), and Sheetij Jain (Product Manager in User Profiling) we’ll answer all these questions and more.
Too Long; Didn’t Read? Jump directly to the questions!
- Meet the Interviewees
- What is it like working at trivago – both on the data science team, and at the company more generally?
- What’s the biggest difference between data science in academia vs data science on-the-job?
- What is trivago’s unique approach to problem solving?
- What were the biggest data science challenges you encountered since the COVID-19 outbreak?
- How have you handled product and A/B testing in a data-scarce environment?
- What did you learn in the process of these reactions to the situation?
- How do you communicate results on projects like these up the org chart and across departments?
- What skills, characteristics, and attributes are trivago looking for in new data science hires?
Note: This article has been adapted from the original Q&A conducted by C1 Insights.
Meet the Interviewees
Andrea Fernández, Ranking-Data Science Lead, joined trivago January 2014
My undergrad education started in the UK where I studied Mathematics. I then went on to do a PhD in Applied Mathematics, modeling chemical reactions before moving to Germany and starting my industry career at trivago. I have been at trivago for 6 years. I started as a business analyst for Public Relations releases. After 1.5 years I moved into SEM (search engine marketing) where I specialized in bidding algorithms and moved into a leadership role overseeing the Marketing algorithms team. In March 2019, I decided to take another jump from Marketing to Product. As part of our product team, I am now responsible for the data science and analytics team in ranking. At trivago, I am also involved in talent leadership.
Sheetij Jain, Alternative Monetization - Product Manager, joined trivago January 2018
Even with a background in Electronics and Communication, it was difficult for me to resist jumping on the ‘Data Analytics’ stream. Data is the new oil they say, and five years ago I started my quest to do more work with this vital resource. Over that period, I got the opportunity to work as an analytics consultant for multiple companies - Microsoft, T-Mobile and Cisco before working at Amazon as a Data Analyst, then ultimately joining trivago as a Data Analyst. With a mindset to productize powerful algorithms to deliver better user experiences, I made the switch to Product Management. As a PM in the Alternative Monetization team, I work on integrating different products within the trivago ecosystem and take data driven decisions on optimizing the overall experience of trivago users while adding a revenue boost to trivago’s topline.
James Neaves, Hotel Search-Business Intelligence Lead, joined trivago June 2015
I have an educational background in mathematics and history, so data science and analytics was not necessarily an obvious choice. Before working at trivago I started my career at the NHS in the UK, before moving into data analytics for university management at Cardiff and Bristol Universities. Six years ago, I made the jump from the academic to the business world, starting as a data analyst for our website and apps at trivago. Since then, I have developed into a team and strategic leadership role, leading the team responsible for user behaviour analysis and a/b testing for our core products. Alongside my team lead role, I am also involved in strategic leadership within the organization both for company strategy and talent leadership.
What is it like working at trivago – both on the data science team, and at the company more generally?
James Neaves: At trivago, data is at the heart of everything we do. This was apparent to me from my first days at the organization. We have really flat hierarchies and even as a junior data analyst, I was involved in discussions with senior leaders at the company who deeply understood the power of data.
I enjoy my work because it’s meaningful, and I have the ability to make an impact, free from organizational roadblocks. Decisions at trivago are made using data and insights, so as soon as I can prove I am going in the right direction, I get the support I need. The company also encourages personal development, internal growth, and job rotations.
We also move fast! When we make decisions, we do it with confidence and put our full energy behind it. This was a big contrast to the traditional annual cycles of the academic calendar.
As an organization, we have six core values - (1) trust, (2) authenticity, (3) entrepreneurial passion, (4) power of proof, (5) unwavering focus and (6) fanatic learning.
In my opinion, Fanatic Learning is what allows data science to drive the business forward. Our team is involved in so many key areas including product testing, marketing spend experimentation, hotel search, marketplace, and advertiser relations. This shows that as an organization, we value data, learning, and experimentation, while also giving team members at all levels the ability to make a real impact.
Andrea Fernández: I agree and would add more detail to James’ point on Fanatic Learning – specifically about the exchange of information across different data science teams throughout the company.
We have several initiatives that originated from individual team members – created by data scientists for data scientists. We also have several specialized guilds in different subjects as well as a more general “meetup” where team members from different departments get the opportunity to present learnings and projects.
What’s the biggest difference between data science in academia vs data science on-the-job?
Andrea: Business is faster-paced, less structured, and more hands-on than academia.
At work, a more pragmatic approach is needed in which one needs to understand the tradeoff between complexity and impact. One should not be afraid to take a more iterative approach, pushing one version at a time, rather than waiting until all the research is done before presenting findings or making crucial decisions.
Another distinction between research and academia is the ground data. Although I believe this is changing, industry datasets tend to have more hiccups, outliers and bugs. When analyzing or building models in industry, one needs to be pragmatic and develop techniques to deal with inconsistencies and data that isn’t clean. In research, however, the outlier is sometimes the most interesting part worth researching.
James: From my experience, the largest skill gap is related to the practical application of data science theory. Our data scientists cannot just focus on building the most accurate model or the best prediction. They must also consider the impact on the business.
At trivago, we try to remain conscious of opportunity costs and return-on-investment. While we encourage failure and fully embrace trial and error, we need to be comfortable dropping projects that don’t show promise while doubling down on projects that do. Understanding the practical impact of data science work is an incredibly valuable skill in becoming an effective team member.
When recruiting, I often look for candidates who have at least one year of experience (including internships), to help bridge this gap. The good news? Most people pick up the ‘business impact’ concept pretty quickly once they begin working.
What is trivago’s unique approach to problem solving?
Sheetij Jain: Data is absolutely our most valuable resource when it comes to solving problems. Once we identify an opportunity, we develop an idea, then substantiate it with data points to truly understand the depth of the problem. Once we have the problem prioritized, we “build a skateboard” instead of thinking about the entire car (see image below). With data science projects in particular, we’ve learned the importance of providing value at small intervals (in smaller shipments) as opposed to waiting too long to get feedback on our models. Here’s what we mean by building a skateboard before working on the whole car:
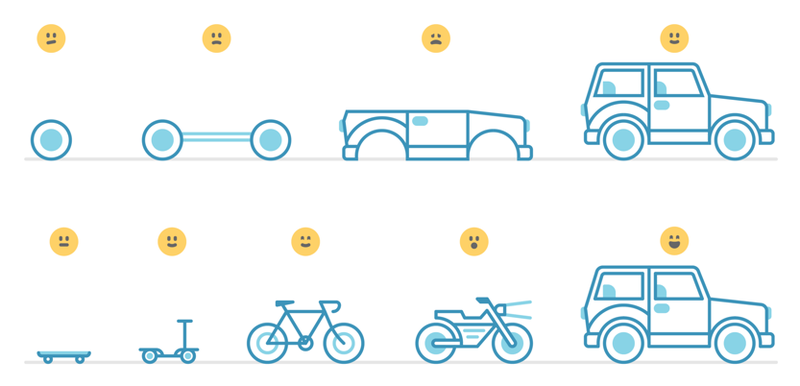
The skateboard is our MVP (Minimum Viable Prototype) that we use to test and gather valuable feedback for future iterations. This is how we approached our most recent project “Concept Recommender” - where the first version of the recommender was based on analysis and a naive model to understand the potential impact of solving this problem. Once we understood the potential impact and gathered the necessary feedback and data from users, it was time to iterate and get closer and closer to our dream car!
For context, the Concept Recommender powers trivago’s ‘More Filters’ section.
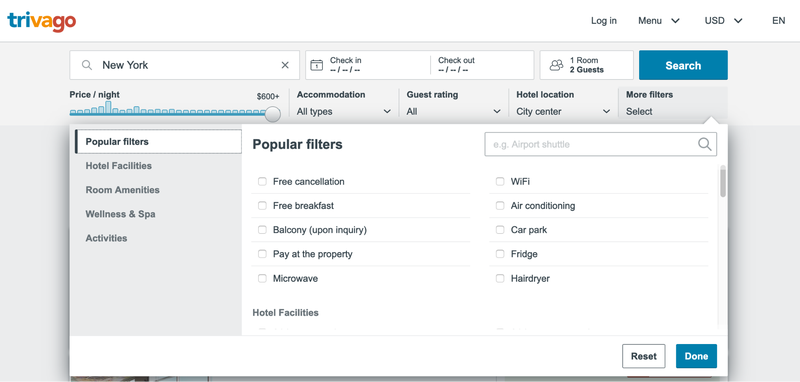
This feature provides users a personalized recommendation of the hotel amenities (“concepts” as we call them) taking a user’s context into consideration.Before this feature went live, our recommendations were based on intuition and business rules. We replaced that old business logic with the power of an algorithm.
What were the biggest data science challenges you encountered since the COVID-19 outbreak?
Andrea: The biggest challenge we faced was the impact on our traffic levels. This prevented us from continuing with our usual iterative testing approach. Furthermore, the testing traffic quality was also impacted. As travel demand dropped worldwide, even the core users that did come to our product had a different travel intent and we could no longer rely on the data to better understand user behaviour. This change to the quantity and quality of our data required a complete makeover of our priorities. We decided to use the time to learn via bolder tests and, on the other hand, also focus on model fundamentals.
Bolder testing gave us the opportunity to bring to life all those ideas that never made it to the top of the list before, because of their anticipated impact or due to its ‘nice to have’ status. We are now using these data sets to have a new basis for our metrics and further understand the dynamics in extreme scenarios, helping us to educate our idea generation.
Model fundamentals took us back to basics and gave us the time to work on our code base, data enhancements and model assumptions. This ensured that once traffic picked up, we could go back to our iterative testing approach with a much more robust and efficient set up.
Another important challenge was the fully remote office set up. In our teams, we are used to having ad-hoc discussions and brainstormings, which were immediately reduced. We needed to quickly adapt to not having someone you can turn around to briefly to get some input. We agreed on a set of guidelines which we continuously revisit in our team meetings and virtual coffee breaks to continue. Some specific initiatives we follow are using our team channel to pose those questions that we would have made to the “room” before, setting up result sharing sessions within the team or adding socialising sessions in which we all have managed to successfully mimic those coffee break conversations.
How have you handled product and A/B testing in a data-scarce environment?
James: At trivago we have an in house A/B testing set up, along with testing tooling adapted to our specific traffic performance. As the effects of COVID-19 on our traffic levels became increasingly clear, we realised we would be in a situation that we hadn’t faced before – one where we had significantly less data to experiment with and learn from.
The first step we took was to change the data used to fuel our understanding of performance to a much shorter time frame, which we use to schedule test durations. Rather than considering the last month when calculating base rates and volume, we switched to a more reactive one week approach. When finishing this, we realised that in a COVID-19 world, our testing duration would require more time that we were really willing to invest for some of our metrics. In a fast-moving product development environment, we want to be able to quickly interpret test results.
The next step we took was to make the decision to make preliminary acceptance decisions based on much lower confidence thresholds or significance levels. In cases where we expected a low effect size, or smaller product changes, we guarded against changes large enough to be concerning from a business standpoint. This allowed us to test even with a lower volume, through taking on more risk. This is fine for smaller changes, but for our bigger product changes we needed a different solution.
This led to our approach of a ‘deactivation test’. This meant keeping a subset of major tests in our codebase, even after we had ‘accepted’ them from a product development point of view. As traffic returned, we were able to make a bundled deactivation test to look at the cumulative impact of the major product decisions we had made in a low data environment. Turning all these features off at once allows us to see the overall change in business performance, though individual cause and effect was less easy to determine.
On running this deactivation test, we were able to understand the cumulative effect of the large feature changes and see that there was an overall positive impact on our key metrics, measurable now that traffic was on the rise. This gave us the confidence in our codebase to fully integrate these features and maximise the benefits of the growth in traffic volume.
What did you learn in the process of these reactions to the situation?
- Data scarcity can be alarming, especially when you are used to a very data-rich environment. It is very easy to take for granted how lucky we are to have so much data to work with, but we miss it if it isn’t there!
- As data scientists and analysts, it’s important to be pragmatic and get comfortable with risk. Explore ways to validate assumptions or confirm findings at a later date.
- A really interesting learning was to see how fundamental statistical concepts are visible in real world settings. Looking at confidence intervals over long running tests and seeing the corresponding effect on our performance measurements from a major increase in variance was a really nice way to see statistics in action.
- Even when our main requirement to be able to do our jobs, data, suffers a big change, it is possible to adapt and continue learning. We had the opportunity to design tests that would have not been possible before due to their bold nature and anticipated high impact.
- Communication once again is key. We made sure to have clear home office guidelines that focus on creating transparency of our work and regularly hold discussions to ensure no big potential opportunity is lost.
How do you communicate results on projects like these up the org chart and across departments?
James: Communicating around data science projects can take many forms and we have different forums for this. We respect data science as a key competency within trivago and increasingly it is at the heart of many key initiatives. In Hotel Search, we often highlight the work of data science teams in our quarterly ‘all hands’ presentations or in our weekly meetups, which are open to everyone from product owners to designers to software engineers.
Outside of our routine business communication, we also have data science and analytic groups dedicated to certain topics, such as machine learning or language specific groups such as Python or R. These groups collaborate on different topics and meet semi-regularly to discuss projects, applications of their work and best practices. Internally, these groups are referred to as ‘guilds’. As a learning organization, cross-department knowledge exchange is really important in getting the most out of our collective experience.
We also reach out to the data science community outside of the organization. We run events such as the Data Science After Work, which we hosted at our campus (pre COVID-19) where we’ve shared insights into the projects we work on with data scientists outside the organization, both in industry and academia. This is also a great opportunity for our people to grow and practice their presentation skills in a familiar environment.
What skills, characteristics, and attributes are trivago looking for in new data science hires?
James: Obviously, keen analytical ability and data science skills are important for us– though we can be flexible with regard to technical skills. For example, on my team I have people using both Python and R. I try to encourage all of us to grow as a team and continually invest in professional development and acquiring new skills.
There are some additional characteristics I look for when hiring, that may not be quite as standard. I am interested in finding people with strong communication skills. Our data science people must often work with product owners and business stakeholders. In these cases, knowing the technical side of data science is not enough, you must also be able to discuss results in a way that non-experts can understand. Great communication skills can turn data into truly actionable insights.
Another aspect that is important is fit within the company. In data science, I see three of our core values that really resonate with exceptional data science talent – fanatic learning, power-of-proof and entrepreneurial passion. While the benefits of a data-driven approach and continuous learning may be quite clear, our ‘entrepreneurial passion’ value means we should all take an ownership and business-oriented approach to the projects we work on while maintaining passion for the work we are doing.
Andrea: Specific data science skills I look for can be broken down into 5 areas. All these should be more or less present and not all are expected to be developed to the same extent. A good team would be able to complement each other in these areas.
- Visualisation - This is in line with James’ comments regarding communication skills. It is important to be able to present and communicate results and insights in an understandable way so all audiences can follow and act.
- Programming skills - Capability to embrace and learn different programming languages to analyse and create models.
- Data Wrangling/ETL Skills: Getting data to a usable format is a challenge in and of itself.
- Modelling: Application and evaluation of different models such as machine learning models.
- Math and Stats: Ground knowledge of the theory behind models and evaluation/testing methods.
Regarding “soft” skills, I totally agree with James. Entrepreneurial passion and willingness to connect data science with business impact is also vital.
If you’re interested in applying for a data science position at trivago, keep an eye out for open jobs here.
Learn more about data science at trivago in our video:



Follow us on