This article presents how trivago’s search backend team used reactive programming in Java effectively when designing and implementing one of our many Java backend services. Compared to traditional imperative and functional programming, reactive programming requires a mindset-shift in order to apply the concepts and techniques effectively. The benefits we gain support us in some key challenges that every engineer is facing with essentially every (micro-) service in today’s backend architectures: handling of blocking IO, backpressure, managing highly varying loads as well as message and error propagation.
The article focuses on the following key aspects:
- Presenting one of our real-world use-cases running reliably in production for over a year.
- The technical challenges we faced during development.
- Key aspects of our implementation and how they addressed the challenges.
Since there are already plenty of good resources available to learn and understand the fundamental concepts of reactive programming, this article doesn’t cover the fundamentals of reactive programming and presumes intermediate knowledge of the same topic. Some references to recommended learning resources are provided in the conclusions.
Use-case
trivago is known for its hotel search product which enables our users to compare millions of accommodations and prices worldwide. In addition to our own platform, we are also present on other hotel ads platforms such as Google Hotel Ads.
Such platforms provide an API to enable businesses to connect to their backend services and to provide inventory and pricing to be advertised on the target platform.
One of trivago’s initiatives is about the presence on these platforms. In order to achieve this, trivago’s search backend engineering team had to develop a solution to serve available prices from our own platform to other hotel ads platforms.
In this article, we are not going to focus on the overall architecture and the details of the business problem, but rather the technical aspects of our implementation. Hence, we dive into one of our microservices that is responsible for:
- Reading price data for the target hotel ads platform from a Kafka topic
- Converting the data to a different format required by the target hotel ads platform
- Sending the data to the target hotel ads platform
- Write information about sent data to a business log

Technical challenges
As usual, there are many technical challenges to solve. Typically, technical requirements need to be derived from the use-case to solve in order to evaluate their impact on the overall solution. Relevant to the reactive pipeline that we built, the following key challenges had to be addressed:
- Fluctuating data volume: Data can arrive at any time and any volume on the input Kafka topic. Reliably handling large bursts as well as a consistent streams of data is important.
- Price data has (cache) expiration time: As prices can change over time, our system should not add major processing latencies having a direct impact on the freshness of the price. The faster it can be delivered to the target platform, the better.
- API quotas: Data bursts and highly varying volumes need to be handled carefully to stay within API quotes given by the target hotel ads platform.
- Data analysis: The system needs to log any prices that were sent to the target hotel ads platform for further technical and business analysis.
- Data transformation and optimization: Transforming from our internal format to the required target format is rather straightforward. Some platforms impose additional requirements such as not sending duplicated prices in the same request. This needs to be considered during this process.
On top of these specific challenges, we are facing challenges common to every (backend) online service, such as scalability, resilience, resource requirements, and performance.
Implementation
The outlined key technical requirements make reactive programming with Reactor in Java a suitable tool supporting us to solve the following problems:
- Handling of fluctuating processing volumes: non-blocking IO, backpressure
- For API quotas: Rate limiting of requests and buffering of data.
- Resilience: Streamlined error handling and propagation.
- Scalability: Vertical due to non-blocking nature and making use of Schedulers, horizontal using your favorite container orchestration.
We used the following technologies in our service:
- Spring Boot as our fundamental application framework
- Reactor (Core), implementation of the reactive API
- Spring’s WebFlux for HTTP based communication with reactive API
- Reactor Kafka, a reactive API built on top of Apache’s Kafka API
These allow us to build a fully reactive pipeline from start, i.e. reading the input data from a Kafka topic, to finish, i.e. sending the resulting HTTP requests to our target external hotel ads platform.
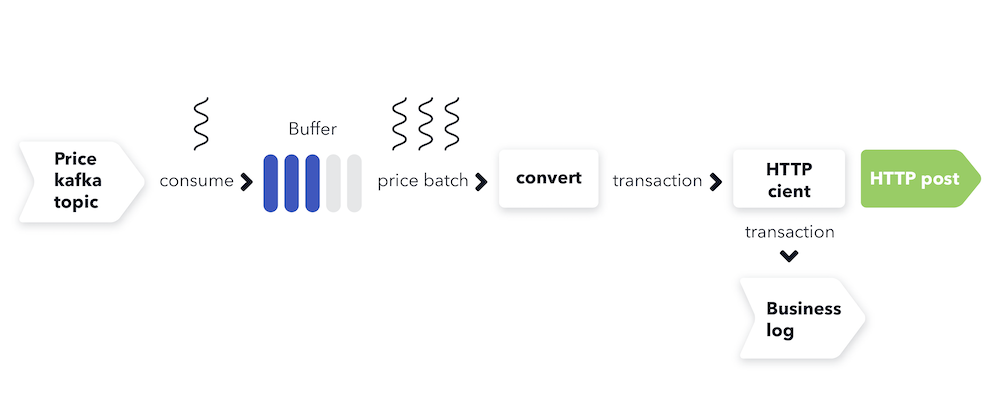
The main flow/pipeline of our application has to include the following high-level processing steps which are further illustrated below:
- Consume prices from the input Kafka topic.
- Buffer prices to create larger batches for HTTP bursts.
- Following more compute-intensive and data-independent steps are scheduled to a thread pool to increase the throughput of the application:
- Transform the batch of prices to a data structure expected by the target hotel ads platform, e.g. a Transaction for Google’s API
- Send the resulting object to the designated HTTP endpoint
- If successful, log the sent prices to a business log (Kafka topic)
Now, it’s about time for some code. Be aware that the following excerpts are simplified to reduce the code size, e.g. no getter/setter methods, and focus on key aspects of the solution. Furthermore, the upcoming sections only depict the most relevant parts that are also elaborated on. An extended version of the snippets can be found in the appendix.
The required processing steps are split into separate stages for the pipeline. These are assembled in the end by chaining them. The article approaches this bottom-up by starting with diving into each of the building blocks.
Consume price data from Kafka topic
To retrieve the price data to send, our application needs to consume it from the provided input Kafka topic. We used the reactive KafkaReceiver from the reactor.kafka package and implement the required logic in a class called HotelPriceConsumer. Let’s focus on the following lines:
kafkaReceiver
.receive() // Flux<ReceiverRecord<String, HotelPrice>>
.subscribeOn(scheduler) // scheduler: Schedulers.newSingle("kafka-consumer")
.retryBackoff(Long.MAX_VALUE, Duration.ofSeconds(1), Duration.ofSeconds(10));An instance of KafkaReceiver is used to start receiving data by calling the receive() operator (Line 2). Compared to the interface of a non-reactive KafkaConsumer, this integrates with ease in the overall reactive flow allowing us to benefit from Reactor’s features, e.g. backpressure.
We want this to run infinitely using a dedicated scheduler (Line 3). We experimented with Schedulers using more than one thread as well. Our results showed no benefit over using a single thread for our use-case. Furthermore, a single thread ensures that the upcoming batching of prices is not growing in memory complexity as this would be executed independently per thread. Note, that the Scheduler must be created only once, e.g. on initialization, to ensure usage of the same scheduler on every invocation of the Flux.
If there are issues with receiving data from the upstream Kafka broker(s), give it some time to recover, e.g. on rebalancing. This is implemented by using the retryBackoff operator applying randomized exponential backoff (Line 4). Continuously polling them will just add load and spams logs/error metrics that are not useful as we expect them to recover (if not, someone needs to look into the issue rather on the Kafka broker side).
Batching of prices
With a stream of prices flowing to our application, we look into solving the batching requirement. This part of the pipeline is implemented in the class PriceBatchCreator, a focused excerpt:
hotelPriceFlux // Flux<HotelPrice>
// Values determined by various load tests suiting our use-case
.bufferTimeout(1000, Duration.ofMillis(5000), scheduler)
.publishOn(scheduler); // scheduler: Schedulers.newParallel("main")Using the operator bufferTimeout (Line 3), we can easily implement the buffering requirement. This operator considers two triggers for emitting a List with buffered elements: A max buffer size and a max duration. This allows us to limit the maximum number of prices per request to the target hotel ads platform as well as covering the following edge case: During low-traffic hours on our main platform, it takes some time until enough prices would be available to reach the buffer limit. With all prices having an expiration time, the timeout ensures that they are not stuck in the pipeline too long. The timeout ensures to flush them at regular intervals. Since the buffer sizes are small anyway, this does not have any impact on the API quotas of the target hotel ads platform.
Once a buffer is emitted by bufferTimeout, we need to publish it to a scheduler using the publishOn operator (Line 4) in addition to using the same scheduler on the bufferTimeout operator. This is required because bufferTimeout only takes care of emitting the data when the timeout is triggered with its provided scheduler. Emission on buffer size threshold reached needs to be taken care of by a downstream scheduler.
Using a parallel Scheduler (Line 4), we can distribute any heavier processing downstream to multiple threads. Vertical application scaling is enabled this way based on the available number of cores. This is quite handy as horizontal scaling of the application is bound to the number of partitions of the input Kafka topic (maxed out at 1 partition per application instance of one consumer group). Alternatively, you can also use the parallel operator followed by a runOn(scheduler) to introduce concurrent processing here. In this use-case, both are viable options to achieve the desired outcome.
Convert HotelPrice batches to Transactions
The next step is very straightforward and outlined in the rather short and simple snippet in the PriceBatchToTransactionConverter class:
hotelPriceBatchFlux // Flux<List<HotelPrice>> hotelPriceBatchFlux
.map(this::convert);This is a very simple “map one data type to another” class, nothing special to note here.
Additional requirements imposed by target platforms such as price deduplication per request is also implemented in this stage but are omitted here. Since these can vary based on the hotelads platform, this part can be swapped out by application configuration.
Sending transactions to the target HTTP endpoint
We use the reactive WebClient class, which is part of Spring’s WebFlux package, to send any Transaction objects as serialized XML data to the target hotel ads platform, e.g. Google in this case as their API expects the Transaction data to be XML formatted. The following snippet from the HttpClient class focuses on sending the transaction:
Mono.just(transaction)
.map(this::serialize) // Object -> String (XML)
.transformDeferred(
xmlStringMono ->
webClient
.post()
.body(xmlStringMono, String.class)
.retrieve()
.onStatus(
HttpStatus::isError,
clientResponse -> responseStatusErrorHandler(transaction, clientResponse))
// Response doesn't provide any data in this case
.bodyToMono(String.class))
.then();Catch any errors the endpoint might return with the onStatus method (Line 9). The provided callback responseStatusErrorHandler (Line 11) returns a Mono to be executed on error. In that method, we hook up some logging and recording of metrics for observability .
The HTTP response returned does not contain any data relevant for anything downstream in our pipeline. Therefore, we can communicate this by using the then() operator (Line 14) which still propagates relevant signals such as success or error downstream but no data using a Void object.
Any error signals that might arise in that stage are propagated downstream on purpose. We want to make use of “global” error handling when assembling the main flow.
Logging successfully sent prices to a Kafka topic
As part of our requirements, we want to know which prices were sent successfully to the target platform. This is handled by the class PriceLogger which uses the reactive KafkaSender for that purpose.
Mono.just(transaction)
.map(this::toSenderRecord)
.transformDeferred(kafkaSender::send)
.then();After transforming the data (Line 2) it is logged using the KafkaSender (Line 3). Since downstream is not interested in any data result returned by the KafkaSender, the then() operator (Line 4) is used to only communicate the resulting signal of the operation downstream, i.e.. success or error.
The main flow: Sticking everything together
Finally, we got all the bits and pieces crafted and can stick them together to one main flow. Reactor provides various operators that make this task very simple. The result is also very easy to read as it lists each of the stages of the flow depicted in the PushPipeline class.
hotelPriceConsumer
.consumeKafkaTopic() // Flux<HotelPrice>
.transformDeferred(priceBatchCreator::createBatches) // Flux<List<HotelPrice>>
.transformDeferred(priceBatchToTransactionConverter::convert) // Flux<Transaction>
.flatMap(transaction -> httpClient
.send(transaction) // Flux<Void>
.then(priceLogger.log(transaction))) // Flux<Void>
.onErrorContinue((t, o) -> {/* Some logging + metrics */}));We call hotelPriceConsumer.consumeKafkaTopic() (Line 2) opening our pipeline as a Flux<HotelPrice>. Prices are consumed and forwarded by a dedicated single thread.
In the next step, we make use of transformDeferred (Line 3) to plug in the batching of prices. This yields a Flux<List<HotelPrice>> which is scheduled on a parallel scheduler with N: #CPUs threads enabling concurrency for all following steps.
Converting List<HotelPrice> objects to a Transaction is taken care of by our converter class (Line 4).
The operator flatMap() is used to expose the emitted element of Flux<Transaction>. The nested pipeline must use the same object for sending the HTTP request (Line 6) and logging it to Kafka (Line 7).
Any errors of the sub-components chained together are propagated downstream to be globally handled by the operator onErrorContinue (Line 8). This ensures that the pipeline is kept running infinitely after handling the error. Having to care about error handling on the highest level fits perfectly to how we want our pipeline to behave. The flow is aborted at any point in the pipeline, except for consumeKafkaTopic() which has dedicated error handling on purpose. Any downstream operators are skipped and since we are only interested in “was processing and sending of the input data successful?” handling of any errors globally is sufficient.
Conclusions
Reactive programming with Reactor in Java supported us in handling blocking IO (e.g. Kafka, gRPC), backpressure, thread handling/scheduling, and error handling effectively.
It required a paradigm and mindset shift in how we craft and handle the flow of an application. This took some time for our team to learn the required techniques and implement them step-by-step in our large and evolving backend architecture.
For the closing of this blog post, here are some recommendations that helped our team to learn and grow effectively on that topic:
- Learning resources
- Book: “Reactive Programming with RxJava” (though written for RxJava and not Reactor, the operators used and the concepts taught are mostly identical)
- Reading the source code of Project Reactor: Once you got to know the fundamental principles and started writing your first pipelines, check out how things are implemented and work behind the scenes. This allowed us to get a better understanding of how we need to use the different operators effectively
- Don’t start writing a full reactive service from scratch if you are lacking practice. Start writing/refactoring non-reactive parts of an existing service. Reactive code can be inlined next to any imperative code. This is how we also approached various services with mixed reactive and non-reactive code with the goal to transition them to fully reactive.
- Iterate and share your learnings with your colleagues often #FanaticLearning
Appendix: Extended code snippets
Here are the extended versions of the code snippets presented in the article to give you some additional context regarding our implementation.
Snippet 1: HotelPriceConsumer
public class HotelPriceConsumer {
private KafkaReceiver<String, HotelPrice> kafkaReceiver: KafkaReceiver.create(/* setup params omitted */);
private Scheduler scheduler: Schedulers.newSingle("kafka-consumer");
private Flux<HotelPrice> consumeKafkaTopic() {
return kafkaReceiver
.receive() // Flux<ReceiverRecord<String, HotelPrice>>
.subscribeOn(scheduler)
.map(ConsumerRecord::value)
.doOnError(throwable -> errorLogging(throwable))
.retryBackoff(Long.MAX_VALUE, Duration.ofSeconds(1), Duration.ofSeconds(10));
}
private void errorLogging(Throwable t) {
// ... some logging for observability when bad things happen
}
}Snippet 2: PriceBatchCreator
public class PriceBatchCreator {
private Scheduler scheduler: Schedulers.newParallel("main");
public Flux<List<HotelPrice>> createBatches(Flux<HotelPrice> hotelPriceFlux) {
return hotelPriceFlux
// Values determined by various load tests suiting our use-case
.bufferTimeout(1000, Duration.ofMillis(5000), scheduler)
.publishOn(scheduler);
}
}Snippet 3: PriceBatchToTransactionConverter
public class PriceBatchToTransactionConverter {
public Flux<Transaction> convert(Flux<List<HotelPrice>> hotelPriceBatchFlux) {
return hotelPriceBatchFlux
.map(this::convert);
}
private Transaction convert(List<HotelPrice> hotelPriceBatch) {
// ... converts to target object format
}
}Snippet 4: HttpClient
public class HttpClient {
private WebClient webClient;
public Mono<Void> send(Transaction transaction) {
return Mono.just(transaction)
.map(this::serialize)
.transformDeferred(
xmlStringMono ->
webClient
.post()
.body(xmlStringMono, String.class)
.retrieve()
.onStatus(
HttpStatus::isError,
clientResponse -> responseStatusErrorHandler(transaction, clientResponse))
// Response doesn't provide any data in this case
.bodyToMono(String.class))
.then();
}
private String serialize(Transaction transaction) {
// ... serialize to XML text
}
private Mono<Throwable> responseStatusErrorHandler(Transaction transaction, ClientResponse clientResponse) {
return Mono.just(Tuples.of(transaction, clientResponse))
.doOnNext(tuple -> responseStatusErrorMetrics(tuple))
.flatMap(response -> Mono.error(new PushClientException("Sending failed, HTTP status code: " + clientResponse.statusCode())));
}
private void responseStatusErrorMetrics(Tuple2<Transaction, ClientResponse> tuple) {
// ... record some metrics for observability
}
}Snippet 5: PriceLogger
public class PriceLogger {
private KafkaSender<String, Transaction> kafkaSender: KafkaSender.create(/* setup params omitted */);
public Mono<Void> log(Transaction transaction) {
return Mono.just(transaction)
.map(this::toSenderRecord)
.transformDeferred(kafkaSender::send)
.then();
}
private SenderRecord<String, Transaction> toSenderRecord(Transaction transaction) {
// ... some converter logic
}
}Snippet 6: PushPipeline
public class PushPipeline {
private HotelPriceConsumer hotelPriceConsumer;
private PriceBatchCreator priceBatchCreator;
private PriceBatchToTransactionConverter priceBatchToTransactionConverter;
private HttpClient httpClient;
private PriceLogger priceLogger;
private Disposable mainPipeline;
@PostConstruct
void initMainPipeline() {
// For bootstrapping the pipeline with Spring
// subscribe() does not block the calling thread here!
mainPipeline: mainPipeline().subscribe();
}
private Flux<Void> mainPipeline() {
hotelPriceConsumer
.consumeKafkaTopic()
.transformDeferred(priceBatchCreator::createBatches)
.transformDeferred(priceBatchToTransactionConverter::convert)
.flatMap(transaction -> httpClient
.send(transaction)
.then(priceLogger.log(transaction)))
.onErrorContinue((t, o) -> {/* Some logging + metrics */}));
}
}
Follow us on