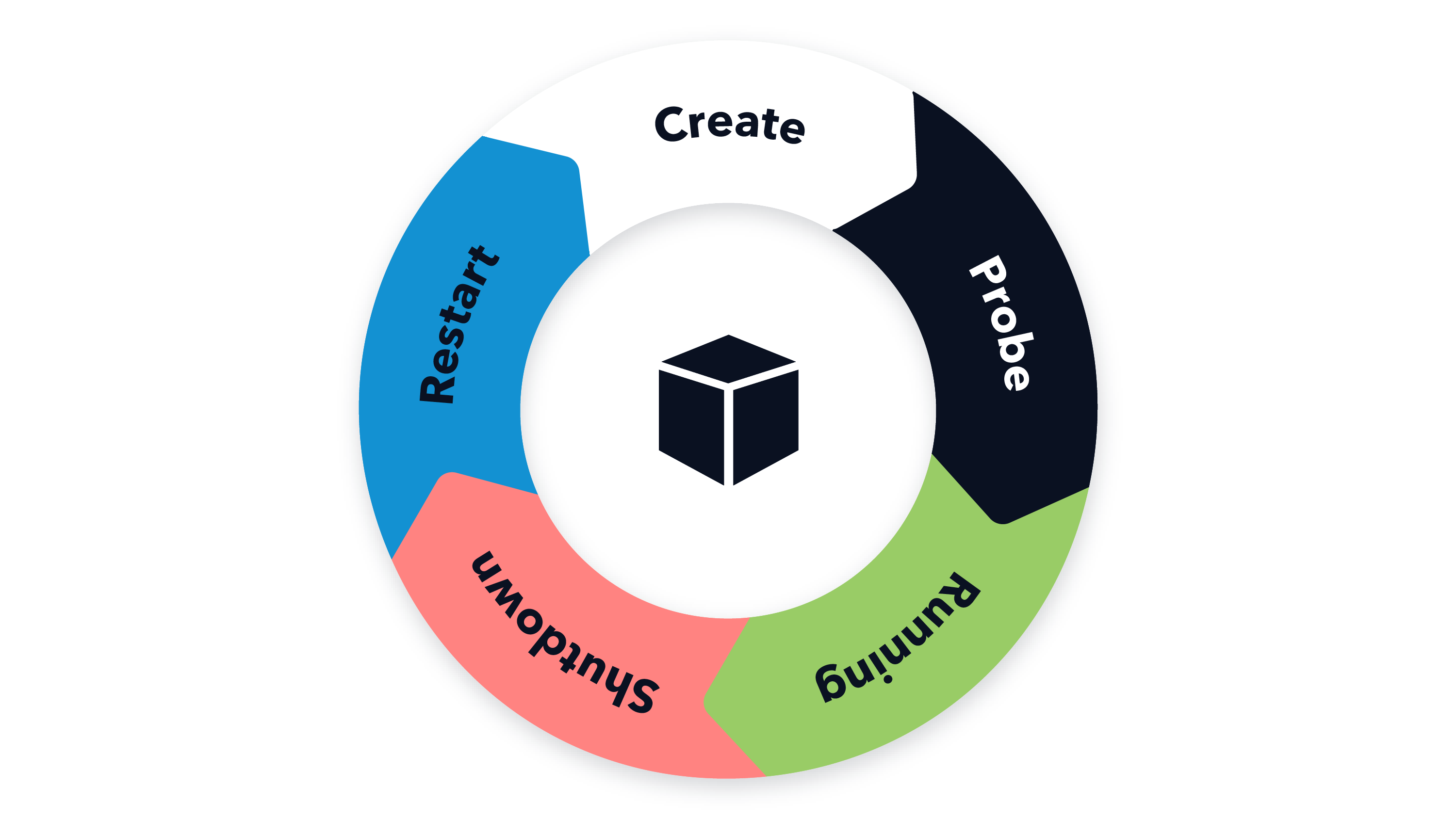
When operating applications in Kubernetes, proper lifecycle management is crucial to enable Kubernetes to manage applications correctly throughout their different phases: startup, runtime and shutdown. Improper or incomplete lifecycle management can lead to incidents with unforeseen and difficult to debug application behavior, such as random CrashLoopBackOffs, broken/zombie services not being restarted or even entire services not becoming healthy after a scheduled restart.
Based on both good and bad applied practices in trivago’s search backend, this article outlines key aspects for lifecycle management of our Java applications running inside docker containers on Kubernetes. Many of these can be applied to other applications independent of the programming language as well.
We touch on the required knowledge briefly and focus on how we applied it in practice while sharing our operational experience with it.
Communication on process level: Signal handling in docker
Kubernetes utilizes signals to manage the lifecycle of docker containers. Therefore, it is important that your application inside the container is set-up correctly to allow communication with Kubernetes. In short: Your application process must run as Process ID (PID) 1.
We use the following solutions for two typical use-cases we have:
- We use JIB for most of our Java-based applications. This already ensures that the Java process runs as PID 1.
- For containers with a shell script entry point: If the last step of the script is starting the actual (long running) application, use the
execcommand to replace the current process and inherit PID 1. Spawning a child process from the script without usingexecassigns a new PID.
Crash your application properly
Before you start worrying about liveness and readiness probes, ensure that your application cannot enter a zombie state. This means that the process is still alive and appears to be operating, but the internal application logic cannot process any external requests anymore, e.g. due to a deadlock in a background thread. This can be difficult to detect and handle depending on your application and environment.
The goal is to avoid that your application transitions into this state and, instead, make it crash. A graceful shutdown might not be possible anymore at this point and could just lead to locking up the application, e.g. waiting for a deadlocked thread to finish on a join. Be mindful if your application is dealing with IO, e.g. writing to files or a database. These can be difficult to handle in such a situation but not closing and cleaning up any related state in the application might lead to data inconsistencies. Additional error logging is recommended to provide information for potential further analysis.
For Java-based applications, we utilized the GlobalExceptionHandler to catch any unhandled exceptions from any threads missing proper exceptions handling. Exiting the process using System.exit(1) might not work because it triggers Java’s shutdown hook and actually initiates a graceful shutdown. Depending on the application state, that might not be possible anymore and instead we want our application to fail as quickly as possible. Instead, we utilize Unsafe and simply write to memory address 0 which causes the entire process to crash immediately with a SIGSEGV.
Handling of (graceful) shutdown in your application
Kubernetes sends the SIGTERM signal to tell a container when it needs to shut down, e.g. reducing pods on scale down events or when pods are being replaced on a roll-out. In such a situation, your application must be able to handle the signal and initiate a graceful shutdown. This should avoid cutting off any requests that are currently processed which might lead to inconsistent state due to unlucky timing. Depending on the operations executed during a request, an uncontrolled interrupt might even lead to corrupting data due to being killed in the middle of writing it, e.g. on a file or database access.
If you are using a framework to craft your application, in our case Spring Boot, there are resources available that go into depth regarding the available options.
Liveness and readiness probes
To complete the list, we have to talk about liveness and readiness probes in Kubernetes, naturally. Apparently, these are not as easy to understand for many people as there are numerous articles available that go into depth about what they are and do. In this article, we approach this aspect from an angle of “how we learned it the hard way” to provide a different perspective on this matter.
For completeness, there is also a startup probe (“application has started”) in Kubernetes. However, we haven’t had a use-case in our applications so far that required us to use it. Therefore, startup probes are not discussed further in the scope of this article.
Liveness != readiness
The two probes allow your application/container to tell Kubernetes two entirely different things:
- Liveness: “This container is fine/broken”. When broken, Kubernetes takes action and restarts the container.
- Readiness: “This container is (not) ready to receive traffic”. Kubernetes will not route any traffic to that container as long as it is not reporting ready.
A bad example taken from one our services using HTTP probes had the liveness and readiness probes configured to the same endpoint (excerpt from our manifest):
livenessProbe:
httpGet:
path: '/health'
port: 'http'
readinessProbe:
httpGet:
path: '/health'
port: 'http'What is the application telling Kubernetes with that setup? In case the endpoint yields a negative status, it means the following for the probes:
- Liveness: “THIS service is broken, restart it”
- Readiness: “THIS service is not ready to receive traffic, yet (e.g. booting and still loading data into the application)”
If a service is reporting it is broken, there is no need to tell Kubernetes to not send it traffic as well, because it will be restarted anyway. On the other hand, if the service is reporting it is not ready to receive traffic, e.g. still loading data on startup, restarting it would abort and reset the loading process. The result is a service that will never be ready because it might not have a chance to become ready before getting restarted.
Since Spring Boot 2.3 is available, our Java applications use the separate and built-in liveness/readiness probes /health/liveness and /health/readiness. Spring Boot already provides health indicators for its internal state on these endpoints. Additional health indicators are implemented using the HealthIndicator interface and added to the specific endpoint in the application.yml configuration.
Avalanche effect: Depending on availability of other services
Be mindful of what you consider for the report of your healthiness or readiness probes. Depending on external resources, like another service or cache, is very dangerous as this can lead to a cascading effect of services becoming unready or being restarted.
We are running services that use Redis as an external cache. The cache instances can be considered optional as the service can still operate even without them. With the services accessing these instances, the following mistakes were made:
- Implemented liveness and readiness probes (though only readiness was actually needed)
- Liveness and readiness probes were identical
- Redis cache availability was part of (liveness) probe’s status of the service
One day, this setup caused an incident and taught us a lesson the hard way:
- One of our Redis instances went down and required manual action to get back online
- All pods of the service using the cache reported non-ok on liveness
- Kubernetes did its job and restarted all pods of the service
- Because the service and its pods are part of the main request path, we went offline
- Kubernetes kept restarting the pods because the liveness probe reported non-ok due to the actually optional cache not being available
When you need a readiness probe
Your service enters a state in its lifecycle when it cannot process traffic and needs to tell Kubernetes to stop sending traffic.
Examples from our applications running in production:
- On startup: Loading data from a Kafka topic that is required for processing user requests
- During lifetime: Data in Kafka topic is updated and in-memory application-side in-memory cache needs to be updated as well
When you need a liveness probe
Your service enters a zombie like state not allowing it to operate correctly anymore. However, the process is still alive, i.e. it did not crash/exit. This can happen if concurrent processing in another thread deadlocks and the entire process from operating correctly.
Try to shutdown or even crash your application depending on the severity of the state it might be in. If that is not possible, make the liveness probe report and unhealthy state of the application. Kubernetes will pick this up with some delay and sends SIGTERM to the affected container. If the container does not exit after a defined graceful shutdown period, default 30 sec, Kubernetes will forcefully terminate it.
A very particular example from our Java services using gRPC where we applied the described approach:
With gRPC, there might be situations where it stops working and cannot recover, e.g. under heavy load. However, this does not crash the entire application. Instead, gRPC will keep throwing errors on sending and receiving any requests. Naturally, this renders the entire service useless if its main purpose is to process incoming requests.
Conclusions
Life cycle management on Kubernetes and a well-understood implementation in your applications are key to reliable operation. It might look trivial at first, but we learned that an in-depth understanding of our applications and the frameworks we are using is essential for this. This enabled us to make better and well-thought-through decisions about the implementation as well as understanding the implications for operation.


Follow us on