
Intro
At trivago we operate on petabytes of data. In live-traffic applications that are related to the bidding business cases we use our in-house in-memory key-value storage-service written in Java to keep data as close to calculation logic as possible.
Having such data stores in public clouds could be quite costly in terms of money and performance, especially if you use applications written in languages with garbage collection mechanics, such as Java. But is there any way how to optimize the performance of such storage-services?
Let’s consider a few use-cases and optimization techniques and show why we use a set of concurrent wrappers around primitive maps.
Bits packaging
Imagine there is a simple Java-record:
public record Bid (int sourceId,
int groupId,
int bidA,
int bidB,
int bidC,
int campaignId) {
}How many bits are needed to store a single record of Bid-object? Let’s calculate. There are 6 integer fields, 32 bits each and 128 bits (16 bytes in 64 bit JVM builds) for Java-object header. In total, we have at least 6*32 + 128 = 320 bits.
Note: Project Lilliput proposes to reduce the Java object header by half or more.
But what if it’s definitely known that each field of Bid-object has a certain cardinality? For example, the maximum value of bidA, bidB, bidC is not greater than 4096 (2^12), groupId and campaignId both have cardinality 64 (2^6) and sourceId — cardinality 16384 (2^14). That means, we could consider that our Bid-record uses only 12 _ 3 + 6 _ 2 + 14 = 62 bits as the payload.
Considering we store not just a few, but billions of such records, let’s compare the memory requirements of each storage scheme:
| Number of records | Approximate amount (Bid-record) | Approximate amount (payload bits) |
|---|---|---|
| 1 | ~ 320 bits | ~ 62 bits |
| 1_000 | ~ 40 Kb | ~ 8 Kb |
| 1_000_000_000 | ~ 37.2 Gb | ~ 7.2 Gb |
It shows that, by having a big data set, we could optimize our memory a lot (~ 80%). But at first we have to pack the bits into some lighter (in terms of memory) data structure.
As you see above, the payload requires only 62 bits, that could be fit in a long (int64) primitive:

Now, let’s try to encode a Bid to a long primitive. The idea is pretty simple: Step by step, we encode every Bid-field into bits, apply int64 bit mask and shift the new value using its own cardinality. For encoding we use a generic BitmaskEncoder:
public class BitmaskEncoder {
private static final long[] MASK_64 = buildMask64();
private final int[] fieldLengths;
public BitmaskEncoder(int... fieldLengths) {
this.fieldLengths = fieldLengths;
}
public long encode64(int... fields) {
long encodedValue = 0;
int shiftStep = 0;
int fieldIndex = 0;
do {
// take a field
int nextField = fields[fieldIndex];
// take the appropriate field length
int fieldLength = this.fieldLengths[fieldIndex];
// take the appropriate mask
long fieldMask = MASK_64[fieldLength];
// applying the mask to the field,
// shifting it and adding to the final value
encodedValue = encodedValue | ((nextField & fieldMask) << shiftStep);
shiftStep = shiftStep + fieldLength;
fieldIndex++;
} while (fieldIndex < fields.length);
return encodedValue;
}
private static long[] buildMask64() {
int maxBits = 64;
long[] masks = new long[maxBits];
for (int i = 0; i < maxBits - 1; i++) {
masks[i] = (long) Math.pow(2, i) - 1;
}
masks[maxBits - 1] = (long) Math.pow(2, maxBits);
return masks;
}
}Here’s an example of how it could work for our particular case:
int numFields = 6;
int[] fieldLengths = new int[numFields];
fieldLengths[0] = 14; // sourceId
fieldLengths[1] = 6; // groupId
fieldLengths[2] = 12; // bidA
fieldLengths[3] = 12; // bidB
fieldLengths[4] = 12; // bidC
fieldLengths[5] = 6; // campaignId
var encoder = new BitmaskEncoder(fieldLengths);Finally, let’s see how we can encode some record into long value:
var bid = new Bid(10, 4, 1, 2, 3, 8);
long encodedValue = encoder.encode64(
bid.sourceId(),
bid.groupId(),
bid.bidA(),
bid.bidB(),
bid.bidC(),
bid.campaignId());What we use for storing primitives
Now we have our bit-packaging algorithm and we want to be able to store our records in some collection.
We could consider standard ConcurrentHashMap<K,V> , but it requires storing key and value both as reference types. This means that, even if we pack our bits into a long value, we would have to store this value in a Long wrapper. This brings with it an additional overhead of at least 128 bits for the Java object header, which we tried so hard to eliminate.
Fortunately, there are several open-source libraries, that offer storing keys and values which allow storing keys and values as primitive values, without boxing:
In production, we use fastutil, because, based on our internal benchmarks, it shows better performance for read and write operations.
The original fastutil library supports the concurrent versions of maps based on java.util wrappers, which has the following definition:
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable {
...
@SuppressWarnings("serial") // Conditionally serializable
private final Map<K,V> m; // Backing Map
@SuppressWarnings("serial") // Conditionally serializable
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
...
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
...You can see that there is a single mutex for the whole map. Such an approach could be very costly in terms of latency of calculation. That’s why we implemented and open sourced our own concurrent wrapper over fastutil maps — Fastutil Concurrent Wrapper.
It works with striped ReentrantReadWriteLock, which gives better performance on reads and holds the lock only per one bucket. There are two different locks mode:
- standard striped Lock,
- striped lock with busy-waiting acquiring strategy.
In situations where you need to have the low latency processing, the second mode, BusyWaitingMode, can provide better throughput and average time per operation, avoiding calling LockSupport.park().
Let’s look at a part of the BusyWaitingMode implementation:
public class ConcurrentBusyWaitingLongLongMap extends PrimitiveConcurrentMap implements LongLongMap {
private final LongLongMap[] maps;
private final long defaultValue;
...
@Override
public long get(long key) {
int bucket = getBucket(key);
Lock readLock = locks[bucket].readLock();
while (true) {
if (readLock.tryLock()) {
try {
return maps[bucket].get(key);
} finally {
readLock.unlock();
}
}
}
}
@Override
public long put(long key, long value) {
int bucket = getBucket(key);
Lock writeLock = locks[bucket].writeLock();
while (true) {
if (writeLock.tryLock()) {
try {
return maps[bucket].put(key, value);
} finally {
writeLock.unlock();
}
}
}
}
...Note: right now, Fastutil Concurrent Wrapper does not support the concurrent version for every primitive map from original fastutil library. Contributions are welcome!
Benchmarks
Now, let’s consider performance comparison between primitives maps and standard Java maps.
For benchmarking, we compared 3 instances with 3 different storage variants each:
- Bit-packaged variant with primitive concurrent fastutil wrapper long-long map (
optimized), - Bit-packaged variant with
ConcurrentHashMap<Long,Long>(optimized-ref), - A simple standard Java
ConcurrentHashMap<Long, Bid>map (not-optimized).
Notes:
- before the benchmarks were run, every instance was deployed and contained
~150million<long, long>records and~1 GBof an additional data. For the additional data there were no writes/reads. - we ran our instances on
Java 16 (openjdk)and with-XX:AutoBoxCacheMax=2700, because there are a lot of relatively small integers.
Writes
Benchmarks were done during one of our heavily-writes period, with ~ 300k max writes/sec for every considered instance:
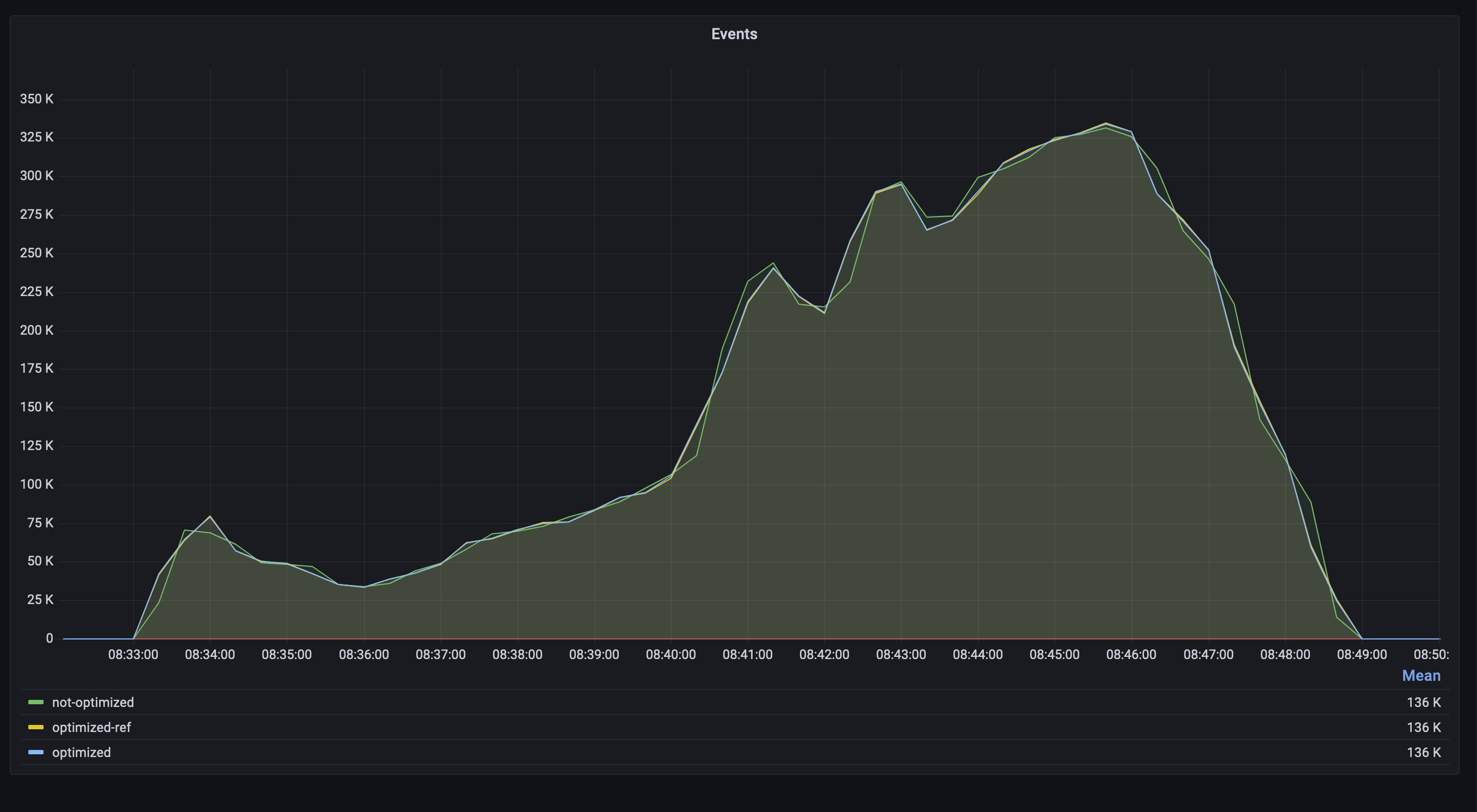
During the writes period, incoming events were writing new key-value pairs and overwriting existing pairs.
Memory
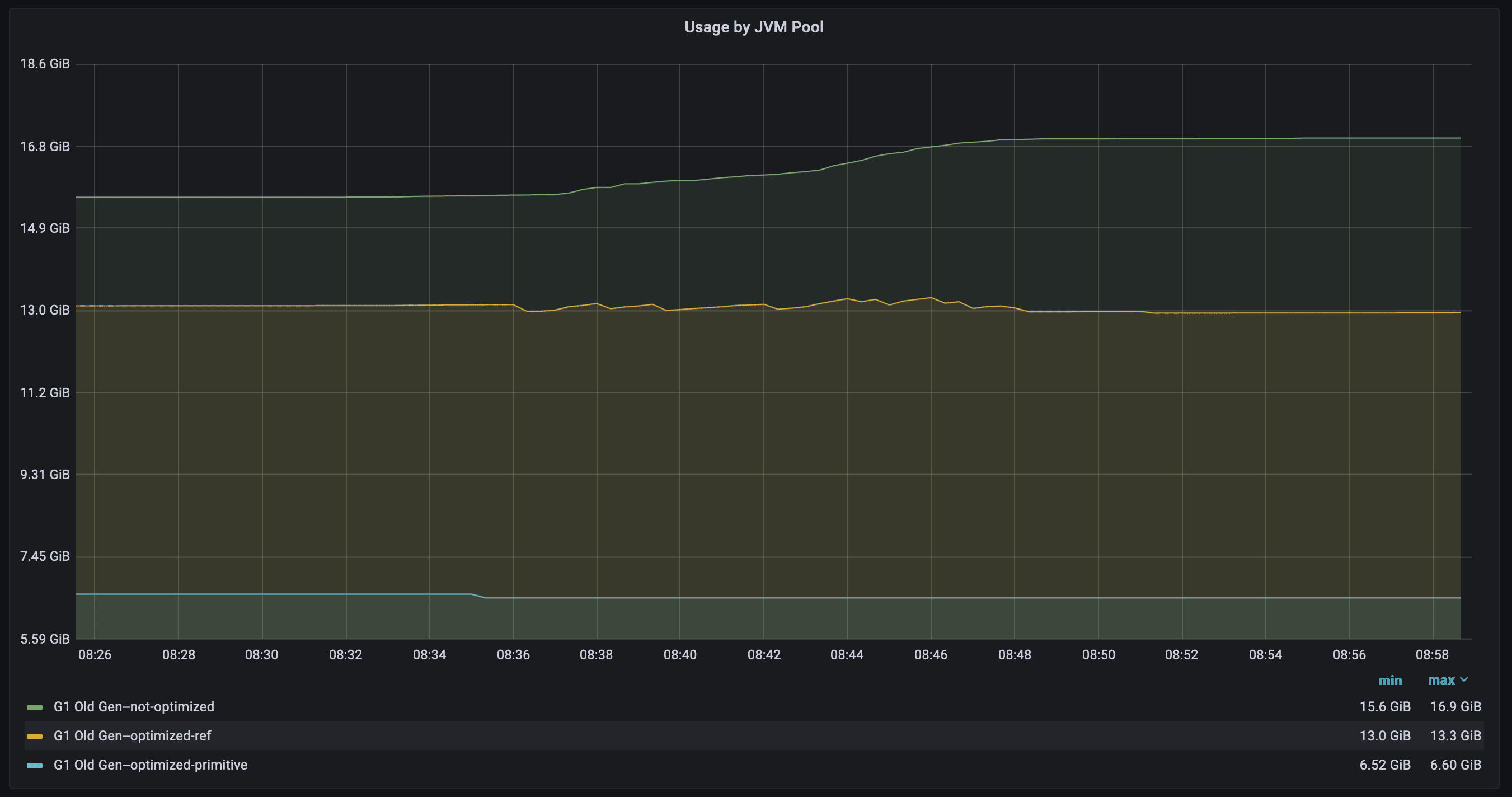
Consider the memory occupation in Old Gen we can see, that our optimized maps occupy only 6.6 GiB max, while other variants with ConcurrentHashMap 13.3 GiB and 16.9 GiB respectively.
The reason for such a big difference is having keys and values as primitives, without any Java-object header overhead and avoiding Java-records.
CPU and GC
Now we check what overhead both Java-object header and structures give to CPU and GC usage:
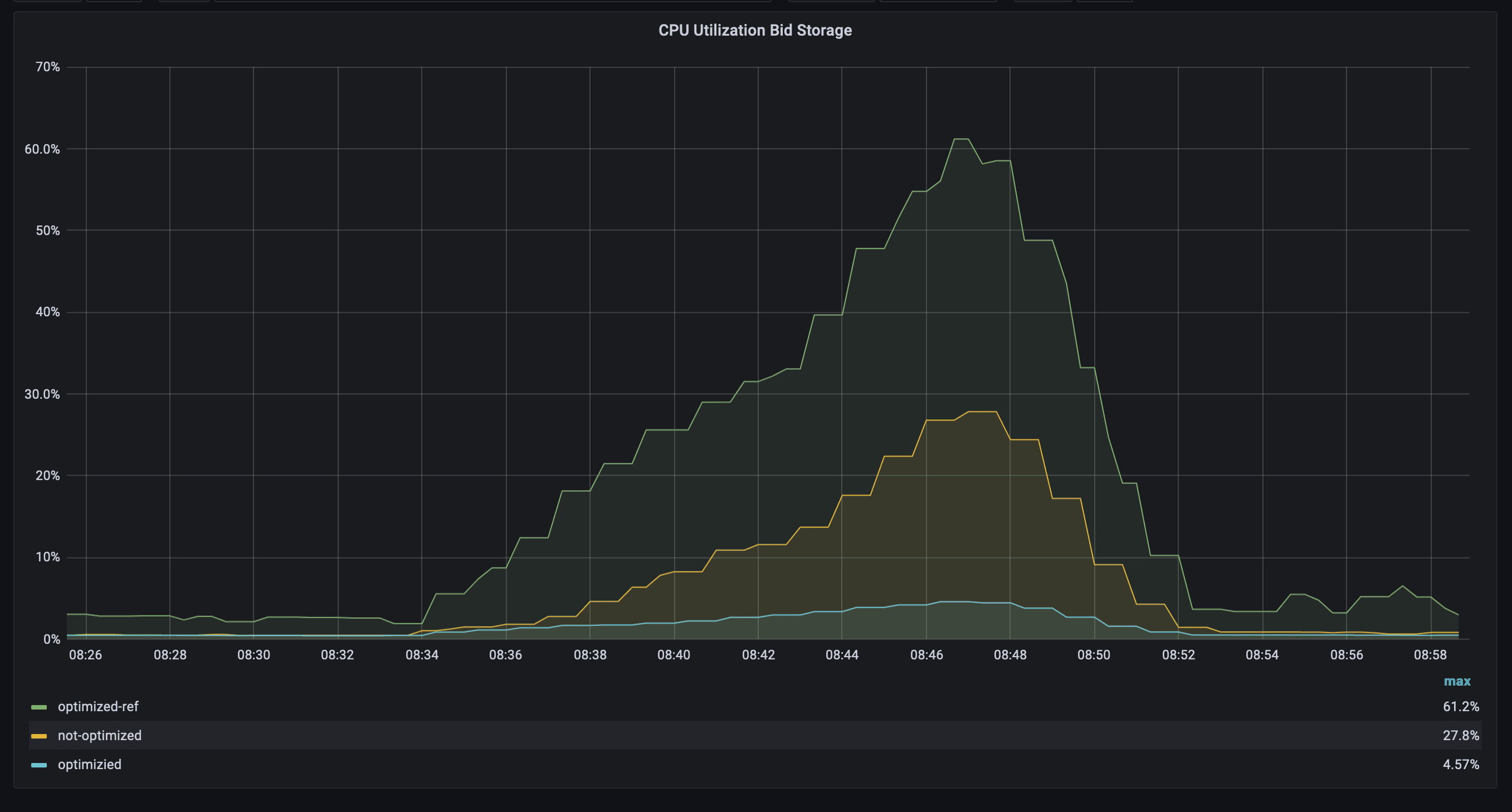
The picture shows how much CPU was burnt for allocating a new piece memory for records as well as GC-work. Interestingly, that not-optimized version has used less CPU compare to optimized-ref. The explanation is: for packaging, the service had to burn an additional CPU, when not-optimized just allocated a piece of memory for records and put it into the map. But most important is: our optimized primitive maps version has burnt much less CPU: ~4.5% vs ~28% vs ~61%.
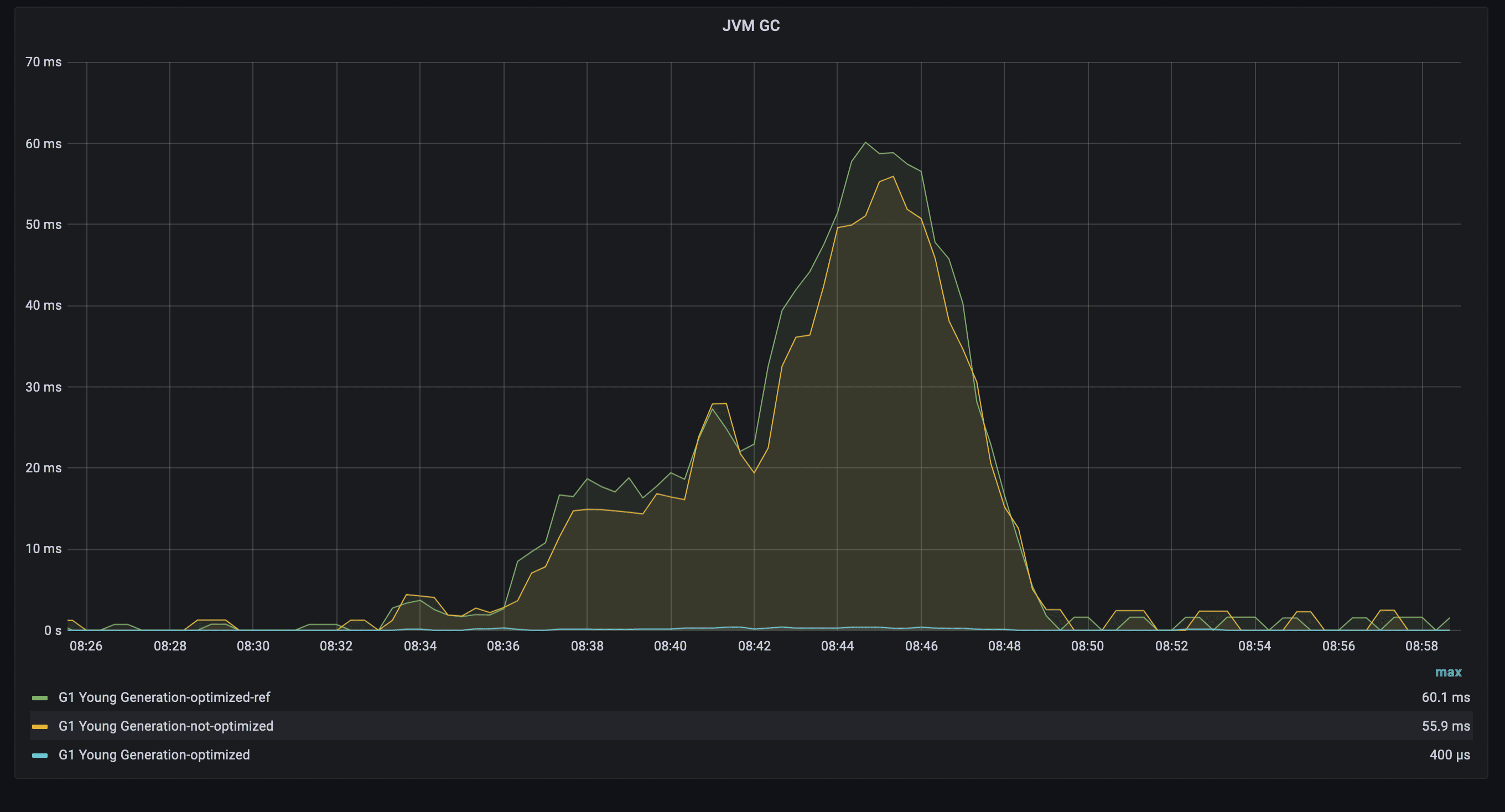
Equally, interesting results for GC (young generation): the Garbage Collector of the optimized version ran for ~400 microseconds, while the other versions ran ~55-60 milliseconds (even with -XX:AutoBoxCacheMax). The difference arises mainly because of large allocations during write operations.
Conclusion
There are a lot of different ways of optimizing your live-traffic application, which could save money and latency. We have considered options for optimizing stored values with certain cardinalities. You could use bits-packaging and Fastutil Concurrent Wrapper, as well as some JVM flags like -XX:AutoBoxCacheMax.
Nevertheless, trivago offers many more interesting challenges to be solved. Check out our open positions if you’re keen to come solve puzzles with us.

Follow us on