tl;dr
Scalability and availability are key aspects of cloud native computing. If your microservice takes five minutes to start up, it becomes very difficult to meet the expectations because adjustments to traffic changes, regional failovers, hot-fixes and rollbacks are simply too slow. In this article, we show how we solved this and a few other problems by taking control of the process of updating our data and storing it in a highly available Redis setup.
Motivation
The trivago backend needs to consume vast amounts of data on advertised accommodations in order to make the best decision about which accommodations to show to our users. Our inventory contains more than 11 million accommodations and for each of them we need access to type information, ratings, coordinates, categorizations, historic data, etc.
Access to accommodation data needs to be fast as there is a user waiting for our response. Hence, in our previous setup, a Java-based microservice consumed all the data on startup, kept it in memory and updated its data on arrival by subscribing to a stream. While this approach shines due to its simplicity, it cannot compensate for its biggest downside: the startup times. Our service required more than five minutes to start.
What can be wrong with reading huge amounts of data on startup?
Consuming gigabytes of data on startup prolongs the readiness to five minutes and longer. We wrote more about the topic of Kubernetes life cycles in a previous blog post.
The long startup times pose a problem to our operations and iterative development:
- Inefficient horizontal scaling: waiting for five minutes until a new instance is ready to serve traffic might overburden existing instances and cause downtimes with user facing impact. That is especially problematic for regional failovers. In case of a data center failure, we can route the entire traffic to data centers in other regions which suddenly induces a significant increase in traffic volume. Or, when there is only a short traffic spike, the traffic might already be back to normal when a new instance has finally started. Furthermore, for resource-based metrics (e.g., CPU load) the autoscaler has to make incremental steps, which can take very long with a slowly starting service further prolonging potential interferences for the user.
- Requires additional precautions: a rollback or hot-fix takes long to deploy. Therefore, one must reduce the risk of a faulty deployment at all costs and implement fallback strategies that increase maintenance efforts. As a workaround we did the following:
- Establish a canary deployment with manual feedback within the deployment pipeline.
- Fallback solutions in other services to reduce revenue loss during a failure.
While the slow startup times are the main issue with this approach, it has more downsides that can be critical, too:
- Every service instance needs to store the entire dataset (~8 GB). Hence, total memory consumption increases significantly for CPU-based upscales.
- Synchronizing the data during runtime of the service can lead to inconsistent results. This happens due to individual instances updating consumed data independently. With the same user session not guaranteed to hit the same instance on consecutive requests, the system cannot guarantee a consistent data view. Furthermore, live updating might result in unpredictable consequences if one is not in control of the produced data (e.g., many updates on a topic slows down the service and can even lead to out-of-memory errors).
- If the consumed data is corrupted, broken or missing, there is no quick solution to roll back to a working state as data consumption and service deployment are independent (i.e., one cannot roll back to a previous data set, only to a different service version).
Architecture
Before we dive into our solution to these problems, we’d like to briefly show you trivago’s backend architecture. In trivago’s backend, data flows in two different circuits. Requests and responses are forwarded from one service to another via gRPC (or other protocols over TCP). The backend services are connected to Frontend/Interface up-stream and to our advertisers down-stream. Source data (input) and business data (output) are consumed and produced via Kafka.
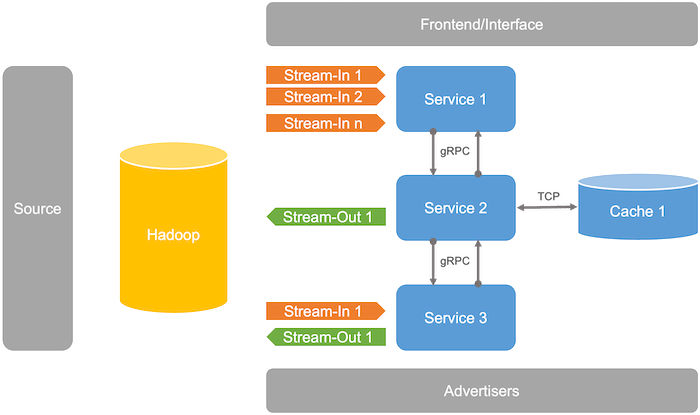
The source data is ingested via a database, a CSV file or any other form by dedicated teams within trivago (simplified and summarized in the diagram above with “Source”). The business data is produced by the backend Java services in the form of logs. Kafka topics are also available in our Hadoop cluster that allows analyzing, manipulating and combining of data.
Solution
Separating the data from the logic
In order to transform our microservice into a lightweight, scalable and reliable unit within our backend architecture, we decided to outsource most of the data to a Redis multi-node setup. We chose Redis because of two reasons:
- Redis stores the data in memory providing fast lookups.
- trivago backend engineers have a lot of experience in developing with and operating Redis as it is used for multiple caching solutions in our system. We wrote about a hands-on experience with Redis before.
We use Redis in a leader-follower setup. All writes are executed against the leader and all reads are handled by the followers. The routing rules - to ensure that each operation ends up on the correct Redis node - are configured via the service mesh Istio. The followers automatically synchronize with the leader in an eventual consistency model. Updates to the dataset occur once per day only, keeping the load for the synchronization of the followers low and well scoped.
In the service processing the user requests, the data for all accommodations relevant to the specific search is fetched in the beginning of the request flow with a single MGET operation. We use the reactive API provided by Lettuce and allow client-side pipelining of operations. This way, we can keep the network overhead minimal. Client-side caching for the most frequently used keys was not implemented because latencies are adequate without the additional layer.
Without the necessity of consuming large amounts of data, the service starts up in less than a minute. That resolved most of the problems in regards to the scalability of the service. We also observed significantly lower scaling demands for the Redis followers in comparison to the service, that is quite compute-intensive. In other words, we need to scale the data less than the computation and can use the cluster resources more efficiently.
From Hadoop to Redis
The accommodation data was consumed from seven different Kafka topics before. To reduce the load on Redis and simplify the access, we decided to combine the data of each accommodation into one Redis value (the accommodation id is the key).
There are many ways to join the data of multiple Kafka topics (e.g., Kafka stream processor). We preferred to join the data in Hadoop for the following reasons:
- All relevant Kafka topics are already available as tables in Hadoop.
- Simple SQL logic that can be maintained by multiple teams and roles within the teams.
- Output data can be analyzed via produced SQL table (e.g., for debugging).
- No additional components to maintain. There is already an established infrastructure around all Hadoop components.
- The workflow can be aligned with other workflows to run when all new input data is available.
- Most of our Hadoop workflows run once per day. Hence, realtime updates are not required.
The updates from the Hadoop workflow are sinked into a new Kafka topic that is mirrored globally. From Kafka, data can be pushed to a consumer via a Kafka Sink Connector. To keep Redis in-sync with the Kafka topic, we use the Redis Sink Connector.
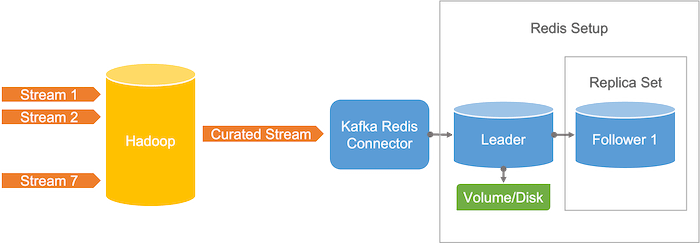
The Hadoop workflow gives us control over the data we push to production. For instance, sanity checks after the join operation can prevent publishing faulty data to production. We also set-up a preview environment to validate changes in a pre-production environment.
Disaster recovery
“Anything that can go wrong will go wrong” (Murphy’s law). Therefore, we implemented a disaster recovery that allows us to replay the accommodation data from a previous day, if something failed on the publisher side (e.g., missing or broken data). The Redis leader persists its databases to a disk. Via Kubernetes, we take snapshots of that disk on a daily basis and keep multiple versions at hand. If the data is faulty in production, we can simply swap the volume and restart the Redis servers. The backend service that serves accommodation data to the frontends will automatically connect to the new Redis instances and proceed with stale but valid data, which massively reduces the scope of the incident and gives us engineers and data scientists time to fix the data.
Conclusion
Keeping all relevant data in memory can lead to fast response times, fewer components and an overall simpler backend architecture. However, in computer science there is always a compromise to make if your workload becomes large enough. We described how reading large amounts of data on startup increases startup times and hence impairs key aspects of cloud native computing.
Our solution is based on well-established products like Hadoop, Kafka and Redis, and basic, well-understood mechanisms (e.g., volume backups). One aspect of the described approach one cannot highlight enough are the opportunities for cross-team and cross-function collaboration. By migrating the join logic from the Java service to Hadoop, we now provide data scientists and analysts, QA engineers and other roles within the company comfortable access to our data. On top of this, our site reliability engineers appreciate the simplification of the CI/CD pipelines - we were able to remove the canary deployment - and our on-call engineers can sleep tighter knowing about the disaster recovery.

Follow us on