
As I’m writing this, we’re in the middle of our yearly load testing process.
Since a couple of years now, trivago conducts regular production load tests. We do this to test if all our services sustain the increased load we experience during the summer and winter months.
This year is now the 2nd time, where we also do another test: A “regional failover” test.
So, what is a “regional failover” test?
Well, we essentially remove a Google Cloud region from production and see what happens.
This year? Not much happened.
But how is this possible? To explain this, we have to go back a couple of years:
The underlying issue
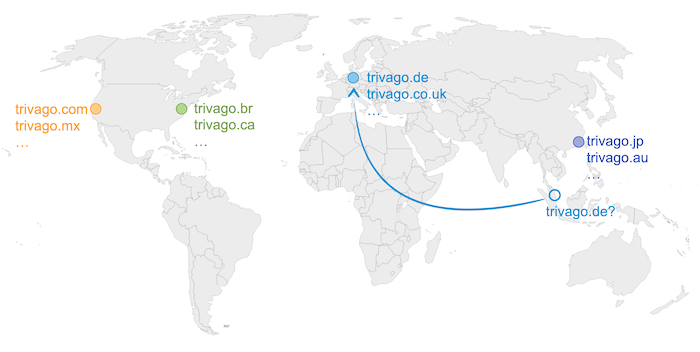
Back in 2015, when we had our first, yearly tech conference, we announced that we wanted to reach “regional independence”. This means that each locale, like trivago.de, trivago.com, trivago.jp, etc., could be served by any, or ideally the “geographically closest”, of our on-premises datacenters.
Back then this was a big thing, because locales were “sharded” across our on-premises datacenters. Means: If you went to trivago.de, you would always be served from Germany, regardless of your geographical location.
Did we succeed with the change? No. The task turned out to be too complex as many systems deeply relied on the regional separation, especially when it came to data.
Back to the future
Now fast forward to the end of 2020. Our infrastructure landscape now looks a lot different. We had just finished rewriting our main backend from two monoliths into multiple micro services. The rewrite included a move to Kubernetes on Google Cloud (GKE). In addition to that we now relied on Kafka, instead of MySQL replication, for transporting our data across the globe. And lastly, we were also closing in on finishing the rewrite of our API backend, which included another migration to GKE. Last but not least: due to the COVID-19 pandemic, our overall user traffic had reduced a lot. In other words: An ideal time to get the topic rolling again.
How we approached it
We started first by assuring that no services were relying on locale based sharding anymore. It turned out that due to the backend rewrite, most services had already removed that dependency. A couple of services were left, but those were mostly easy to adjust.
From the infrastructure side we were also good. All we had to do was to increase the maximum capacity of several components, so that all regions could - in theory - handle the same amount of data and traffic. As all services were already located in Google Cloud, this turned out to not be much of an issue.
Then we looked at our ingress setup, which essentially looked like this:
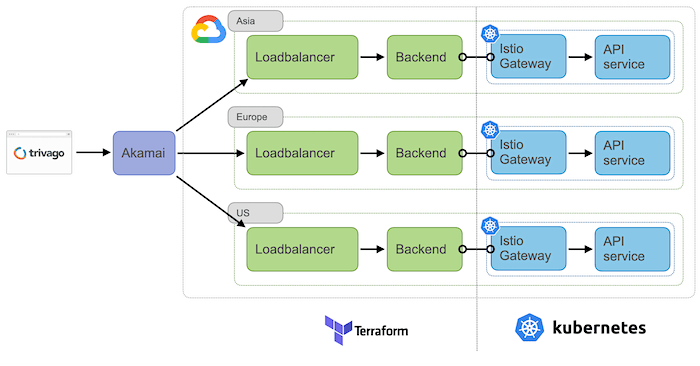
Requests first go to Akamai, which, based on the locale used, decides which loadbalancer to use. These loadbalancers would then forward requests to the corresponding Istio ingress gateway in their assigned region.
During the backend migration we had decided to separate the management of our Google Cloud ingress from our Kubernetes ingress. While originally targeted at making cluster-recreation less painful, this decision turned out to also make the migration process a lot easier: We could simply create a parallel, global loadbalancer and attach all our existing, regional backends to it without having to touch our existing setup.
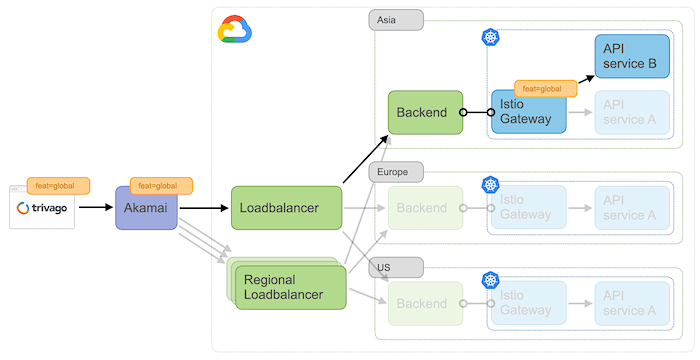
To properly test the new ingress, we added a rule in Akamai so that traffic was split between our existing, regional loadbalancers and the new, global one based on a weight.
And here is the cool thing: we hid this routing decision behind a feature flag header, which was passed all the way down to each micro service. This way we could transparently route traffic even inside our Istio service mesh, based on whether the traffic was regional or global. This proved to be useful for services who were still in the process of having their locale based sharding removed, or where the teams were unsure about their implementation working as intended.
Validation of the results
Another benefit of having the whole process behind a feature flag, was seeing the effects of global routing in our business metrics. The results were actually interesting:
For most locales, not much changed, so our sharding was spot on with more than 99% of our users being routed to the same region. But for some locales, especially those at the geographic “edge” between two Google Cloud regions, we saw about up to 47% of our users distribute to two or even three regions. In about 17% of our locales this affected more than 5% of our users. This “splitting” of users was not a huge surprise though. For countries like India, which is rather large and at the edge between asia and europe from a latency perspective, we had predicted a “north-south” split. And this is exactly what we saw happening.
All in all we were very happy with the results.
The whole move to global routing was finished just in time for the summer load test in 2021. And that’s when we conducted our first “regional failover” test: simulating a regional outage. To do this, we simply scaled the Istio ingress gateway in one of our regions to zero.
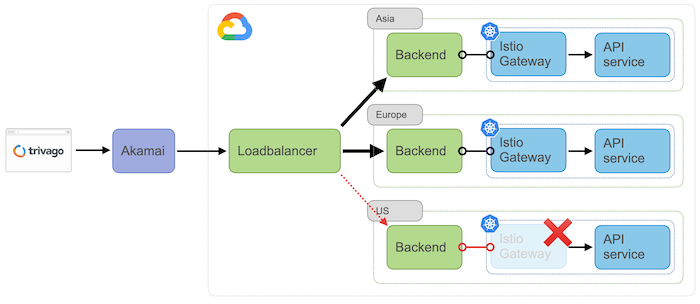
Turning it off and on again
Within seconds, the global loadbalancer started distributing traffic to the nearest working region. Everything worked well, except for a few old services, located in our on-premises datacenters, which still relied on regional sharding. This was a known issue at the time, and was removed shortly after. So, all-in-all a huge success.
The surprise came when we switched the traffic back on: Here is the thing: if you do a failover test while a decent amount of users are active on your platform, all this traffic will come back to the original region at the same time. Very quickly.
So, by switching the region back on, we had actually conducted a “load test by accident”. Luckily we were able to handle the traffic so not much happened.
Another surprise was reported a few days later. As we chose Europe as the region for our test, most of the EU traffic went to the US, which at that point in time (middle of the night) had almost no traffic.
Now we need to speak about a “little” detail. We query prices and accomodation information from our “Advertisers”, like Expedia or Booking. As a matter of fact, if our load increases, so does the load on our Advertisers. Our servers were able to handle the quick increase in load, but the servers of one of our advertisers didn’t.
We’re still sorry for that!
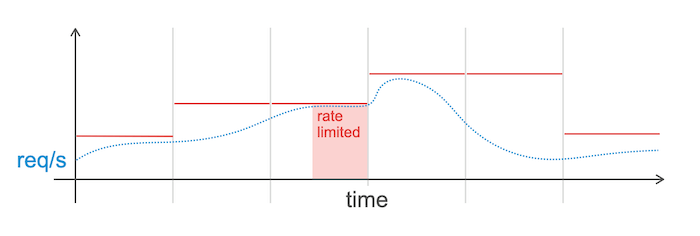
For the coming failover tests we worked around these issue by choosing another region with less traffic. We also started implementing a feature that we call “increase based rate limiting”.
This feature works like a classic rate limiter, but it uses a flexible threshold that automatically adjusts to traffic using a time window based approach. If the traffic increases too fast, we limit traffic. After some time, we increase the threshold based on demand and repeat the whole process.
This gives our infrastructure enough time to scale up and also protects us against other sudden traffic spikes.
What’s left to say
All in all, we’re very happy with the results.
Not only are we now able to serve our users faster, we are now also more resilient on regional outages. Even the complexity of our code was reduced. For example: we did not have to cover cases for “unsupported” locales anymore.
Without our prior investments in technologies like Kafka, Istio, Kubernetes and also our move to Google Cloud, this would probably not have been possible. It’s always nice to see all these things coming together to build something that we previously thought to be impossible.

Follow us on