In the last few years, organisations have been increasing their investments in building Machine Learning (ML) based systems. In practice, such systems often took longer than expected to be built or failed to deliver the promised outcome. Data availability and quality have been among the most significant reasons behind this phenomenon. Since each organisation had its custom problems, open datasets or even logged data were not always directly usable. As a result, data collection and annotation processes became more crucial, yet remained under-documented.
It seemed that the spotlight has always been on the model development part. People preferred to talk about how they tweaked their algorithms, outperformed others on benchmark datasets or came up with a new approach. These ML modelling aspects became the trendy themes because many viewed them as more valuable or “cool”!
Behind the scenes, though, everyone had to deal with challenges related to data curation, labelling, cleaning, etc. However, the practical lived experiences were rarely shared as it sounded like a less important topic. So, any newcomer to the field would hardly find practical tips related to data labelling and curation, as if labelled data magically appeared and grew on its own.
The Data Centric AI Movement
A shift in the data/AI community’s collective mindset has recently been taking place as different entities started to focus more on datasets and benchmarks. For instance, the Data-Centric AI, a concept inspired by the work done by many data practitioners for years, has recently been highlighted as “the discipline of systematically engineering the data used to build an AI system”. In addition, the leading conference Neural Information Processing Systems (NeurIPS) added the Datasets and Benchmarks Track, acknowledging that “Datasets and benchmarks are crucial for the development of machine learning methods, but also require their own publishing and reviewing guidelines.”
In this article, we will share practical tips and lessons learned from several data annotation projects, focusing on a specific use case. We believe anyone involved in such projects will find it useful while designing a data annotation process.
Why is Data Annotation Essential at trivago
At trivago, we import and combine different types of data from different sources. In order to give a better experience to our users and power our products, we continuously work on solutions to enable us to get the best out of the huge amount of data in trivago’s inventory, in addition to mapping and inferring more features. For instance, we work on various themes, including but not limited to:
- What is the accommodation type mapping given a set of features?
- How to tag images using high level concepts beyond certain objects?
- What is the objective quality score for certain content type (images, reviews, descriptions, etc.)?
- What is the right match for a new imported accommodation in trivago’s inventory?
- and much more…
While tackling new use cases, reframing existing problems, or testing different models, reliable labelled data is required for experimentation and benchmark creation. But how to achieve this goal?
What to Consider When Starting a Data Annotation Process?
When faced by a problem requiring the collection of reliable labelled data, one of the first suggestions that pop up among many teams is to fully outsource the manual annotation tasks from day one. The key perceived benefit of outsourcing is having an easier, faster, and more cost efficient process. But is it always the case?
In our case, we knew that we wanted high-quality reliable data that fits our guidelines and use cases. We were aware from the very beginning that any choice would come with a tradeoff. To be able to evaluate different options, we started by asking the following questions that can be useful for any team, regardless of the problem or type of data:
- Are there clear annotation guidelines to help all annotators (internal or external) make consistent decisions?
- What is the level of agreement among internal annotators in the first place?
- Is there a process to enable continuous refinement of guidelines and tags definitions?
- Does the annotation platform allow the design of proper tasks to obtain the required data?
- How easy is it to deal with the annotation platform through an API to automate tasks creation and results extraction?
- Is it possible to train external annotators and create a continuous feedback loop?
Deep Dive: Designing the Data Annotation Process
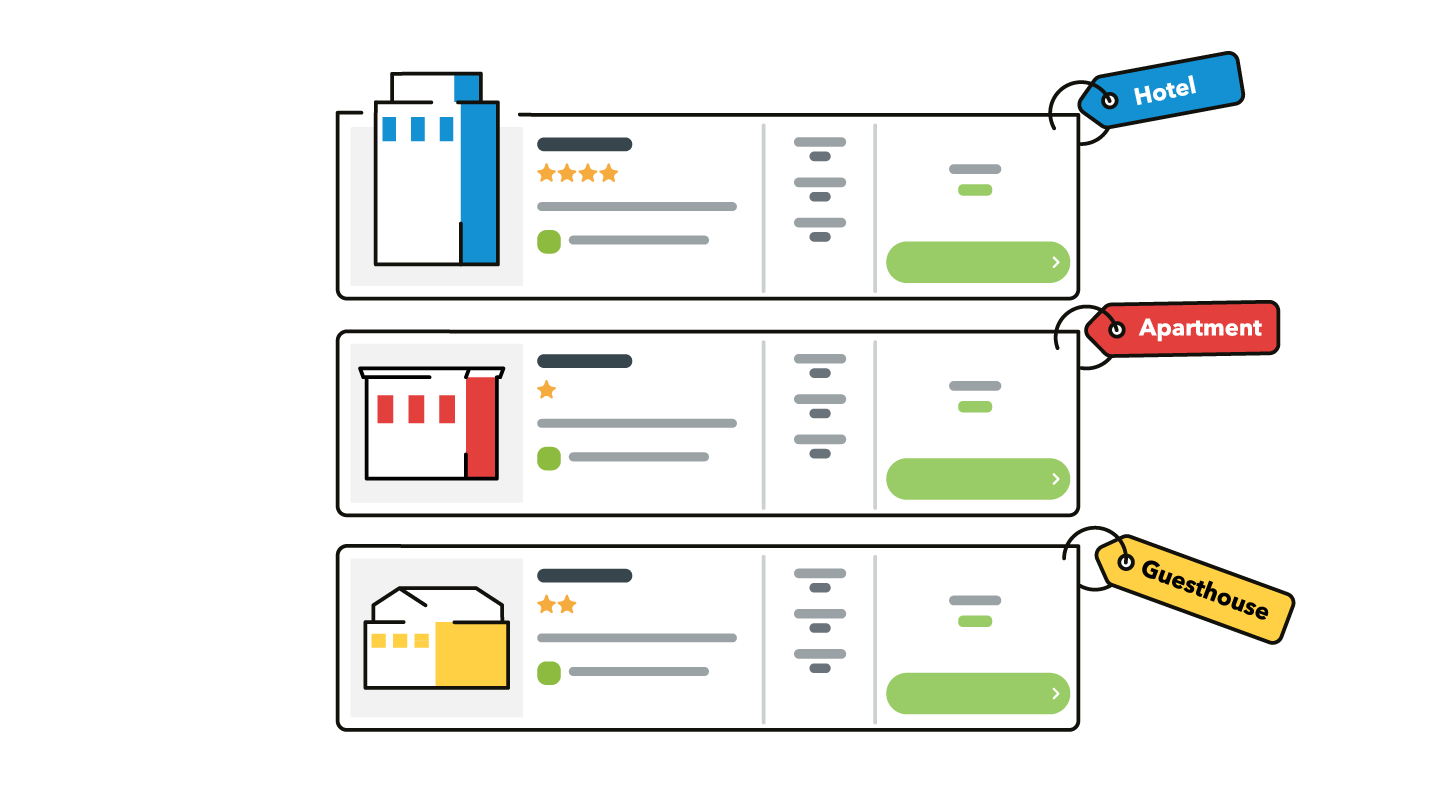
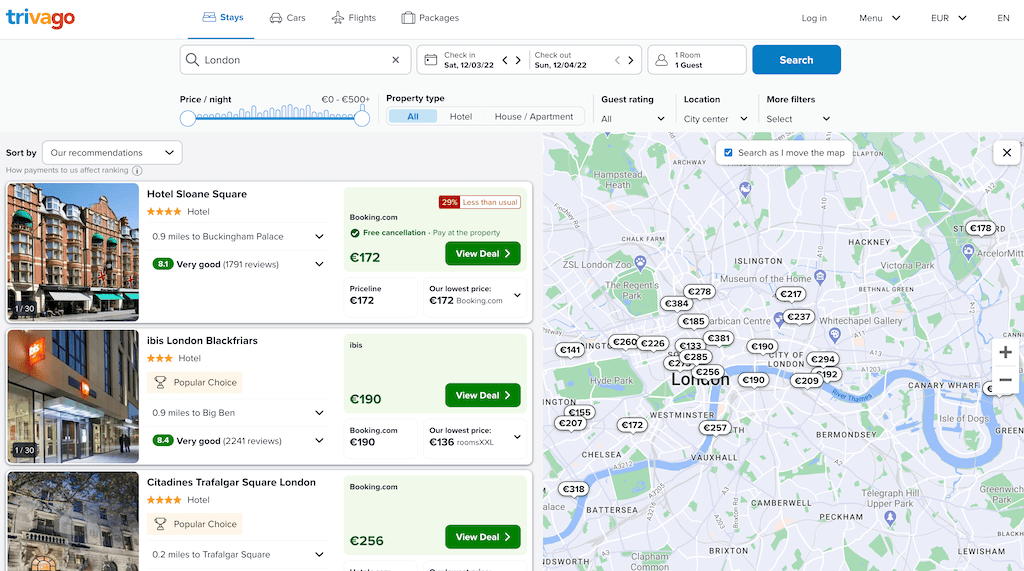
So let’s see how we dealt with such questions while working on collecting labelled data for an accommodation classifications model where the question “What is the accommodation type mapping given a set of features?” was asked. When we talk about accommodation types, we mean categories like Hotel, Guest House, Serviced Apartment, etc. You can see this list if you use filters on trivago’s app as shown in Figure 2.
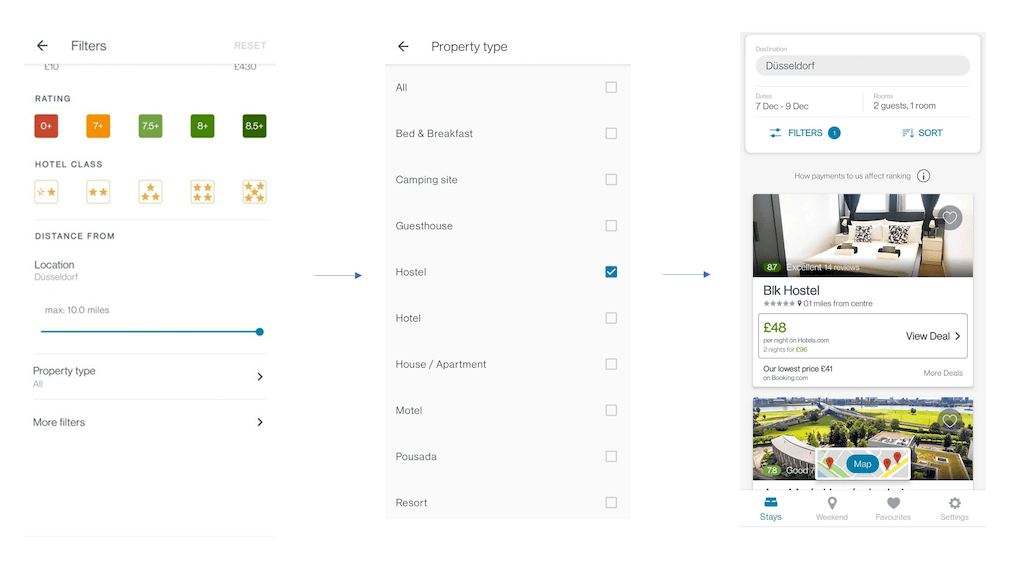
It is worth noting that, when a new accommodation gets added to the trivago’s inventory, it doesn’t necessarily have its type included in the imported data. Moreover, advertisers might provide a different mapping that cannot be directly used or have different interpretations. A valid argument here would be to enforce stricter criteria and a unified mapping on any data provider, but in reality there are many caveats that impact the final data we get.
Given the additional features available about the accommodation, we started to work on a model to classify accommodations according to trivago’s criteria. The first step was definitely creating a new training dataset with ground truth labels. This is why we attached significant importance to the reliability of the data collection process, so we started with the guidelines.
1.Annotation Guidelines
Are there clear annotation guidelines to help all annotators (internal or external) make consistent decisions?
Writing guidelines might seem like a simple one-time task, but in reality it is an iterative, collaborative process. It is important to keep in mind aspects that might impact the outcome and propagate to the next steps such as guidelines decay, implicit knowledge and bias effects.
Guidelines decay
When it comes to annotation guidelines, there are two scenarios; having no guidelines in case of new problems or having old guidelines from previous iterations. The latter might seem to be a better starting point, but it might be tricky because it can add bias to how the team performs data collection.
In our case, we had a set of old guidelines that was so broad that it left a room for confusion/interpretation which made it less relevant. One of the reasons was that alternative accommodations (e.g. Apartments, …) were not common in trivago’s inventory a few years ago. So the nature of the inventory itself has changed over time, presenting new cases, and hence the need for more clarity in addition to frequent updates for the annotator guidelines.
Implicit knowledge and bias
It is a common pitfall that people immersed in a given project are highly aware of the associated context and assume that others will see it the same way. This is an assumption that should be challenged. Testing with a few internal and external annotators made it easier for us to identify some of the tiny details and edge cases that needed to be explicitly included in the guidelines.
For instance, the perception of accommodation types varied across the world. A simple accommodation with standard rooms and few facilities in some countries was considered a Hotel, whereas in Europe and the US it was closer to a Guesthouse. Having a diverse team in trivago from all over the world helped us verify our assumptions and understand such caveats.
Taking all this into consideration, we worked on identifying sources of confusion and subjectivity, incorporating feedback and combining everything together. As a result, a new version of the annotation guidelines was produced. This was only the beginning since we had to ask the next question about the level of inter-annotator agreement.
2.Annotations Consistency/Inter-Annotator Agreement
What is the level of agreement among internal annotators in the first place?
In the previous phase, we wanted to know whether the guidelines were clear enough. We mainly focused on general agreement and qualitative evaluation to move forward. However, we didn’t dig into standard quantitive metrics to measure consistency. To do this we started a new round of annotation tasks internally to measure the Inter-Annotators Agreement (IAA). In principle, this is useful when no ground truth exists to which annotators’ answers can be compared. It also helps identify ambiguities, assess annotators, reveal different valid interpretations for the same instance and gain insights into the nature of the underlying data.
It is worth mentioning that this step should be done with a fixed pool of annotators to be able to calculate the IAA metrics and have calibration sessions in order to discuss disagreements and ambiguities if needed, which was the next point to tackle.
3.Calibration/Guidelines Refinement
Is there a process to enable continuous refinement of guidelines and tags definitions?
By utilising the IAA metrics, we could get a better idea about the least consistent pairs of annotators. We had hypotheses about the reasons behind the disagreements and we wanted to check them out.
We started calibration sessions, which were extremely useful as they gave us the opportunity to discuss our assumptions, why we followed or broke the guidelines and how our backgrounds impacted our decisions. The main outcome of these sessions was an update to the guidelines, including more examples and explicit details about things we assumed were clear to everyone. As we viewed the guidelines as something dynamic that evolved and got refined based on feedback, these calibration sessions became an integral part of the process of dataset and guidelines creation.
We would say that there is nothing better than talking to annotators and letting them explain their logic for better guidelines refinement. But there is one more thing that we needed to talk to them about: the user experience during the annotation work.
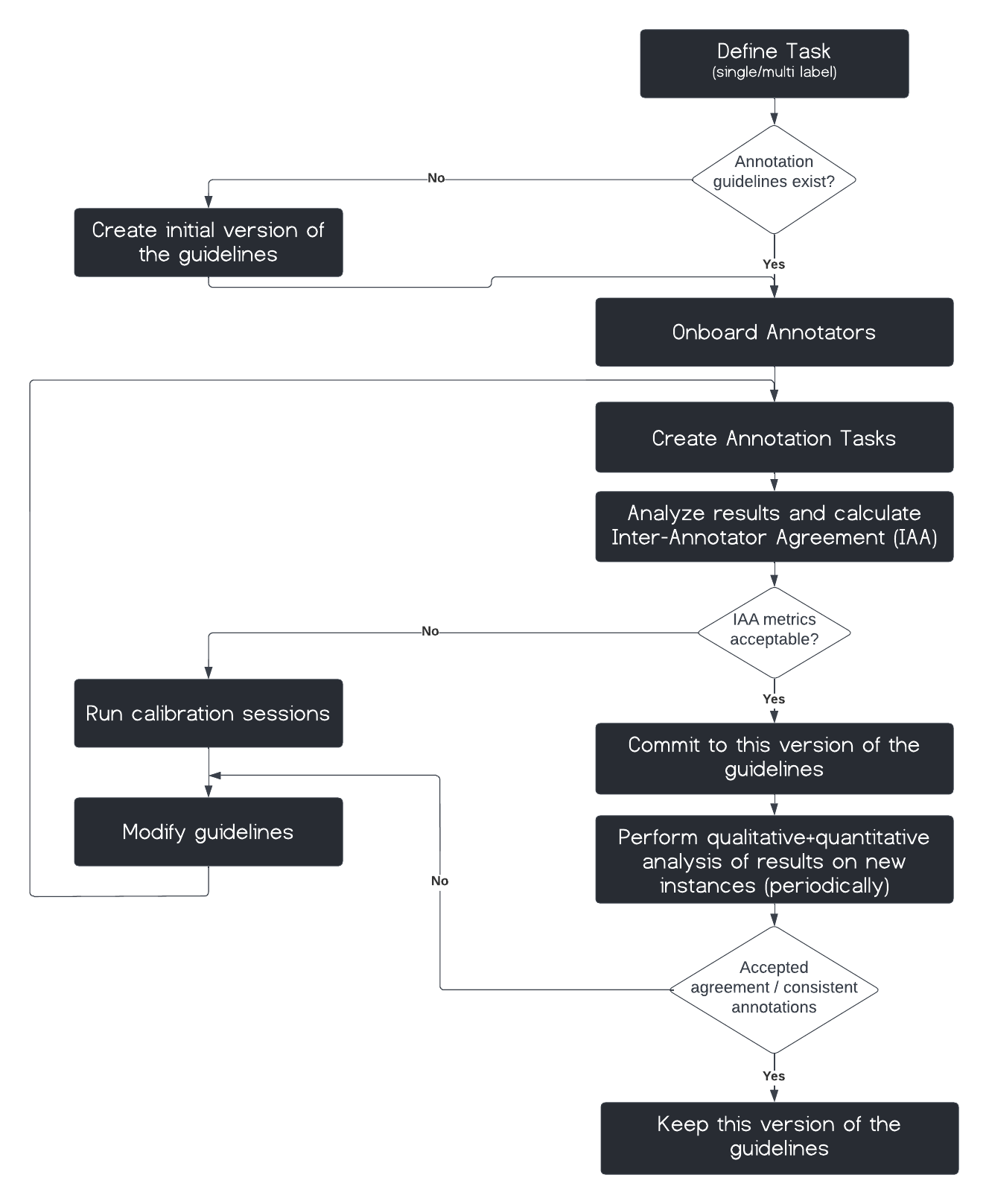
4.Annotation Platform/task Design
Does the annotation platform allow the design of proper tasks to obtain the required data?
Until this point, we have not mentioned how we got the annotation tasks designed, created, and refined. In fact, this was one of the things which we paid the most attention to, knowing how the user experience would reflect on the outcome. We viewed our annotators (internal or external) as users who deserved a smooth experience while doing this crucial job.
In particular, there were two main points to consider:
Which platform to use.
The main objective was to find a platform/tool that fits predefined criteria related to features, flexibility, compatibility with our infrastructure, ease of process automation and availability of ML-assisted labelling. It is common that teams get drawn to the big platforms that belong to cloud providers, but they are not necessarily the most convenient for each use case. We tested different tools, then picked the one that ticked most of the boxes.
How to design the annotation task.
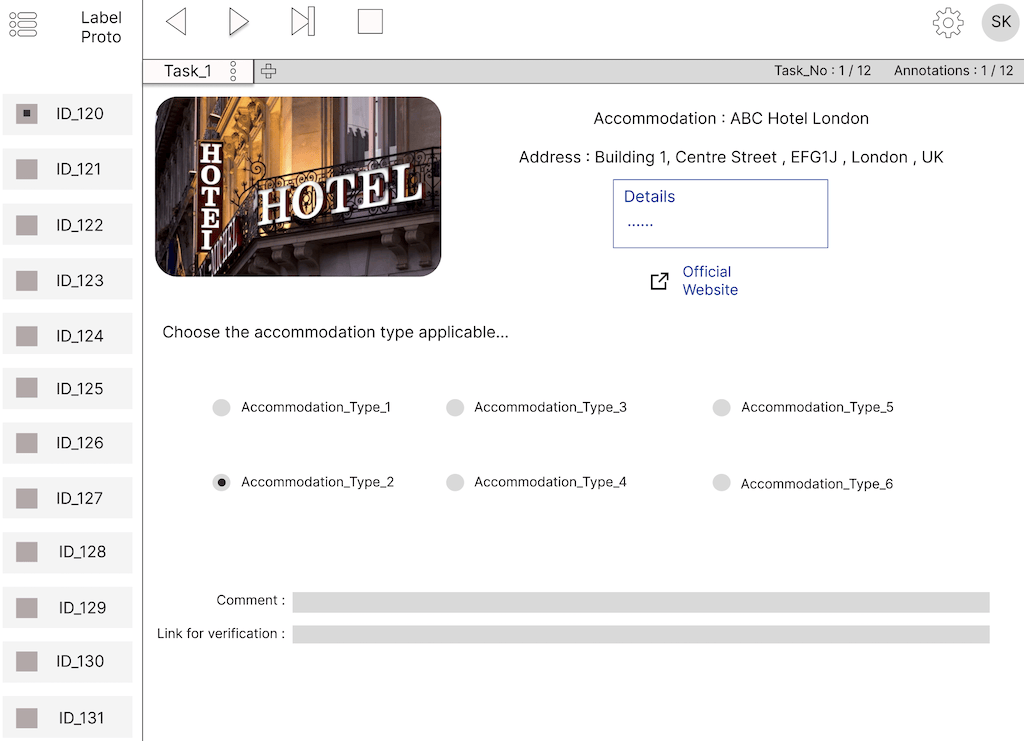
The main objective was to get data in the required format while reducing the cognitive load experienced by the annotators. We started by creating various prototypes with different layout, wording, options and input components as shown in Figure 4. However, we were aware that we could benefit more from other teams whose daily work touched these design aspects, like User Research and User Experience. We reached out asking them to challenge our preliminary design, give tips and help us reach a final design. With continuous feedback, we could see opportunities for improvement and got them implemented, that’s why it was not just a one-time process.
5.Process Automation
How easy is it to deal with the annotation platform through an API to automate tasks creation and results extraction?
As we started to go through several iterations, we settled on an annotation platform and the task design. At this point the process became better defined which helped us identify the bottlenecks and opportunities for automation. Since the selected annotation platform provided an API, which was one of our criteria, it was easy to write scripts to create annotation tasks, export results, standardise the format, and even integrate with Google Cloud Services (GCP).
It is highly recommended to think about the flow of your data whenever you develop data annotation processes especially if it is not a one-time process or if it will be a part of a continuous monitoring or an active learning loop.
6.Feedback From Annotators
Is it possible to train external annotators and create a continuous feedback loop?
Settling on an annotation process in addition to a set of guidelines might seem like the ideal final outcome. At this point, one might feel that it is safe to outsource everything to a group of external annotators. This might be ideal if a given organisation doesn’t have enough capacity of internal annotators. As a team, we considered outsourcing during our data collection projects. However, being aware of the caveats in our data, we preferred to have a trained trusted group of annotators to partner with instead of a random pool of external annotators. This approach allowed us to have an open feedback channel and ensure better consistency during the collection process.
Such an arrangement might cost you more in terms of money and time, but the investment is worth it and this is part of the mindset shift we would like to see in the field if we are to improve data quality during the collection phase.
Conclusion
Despite the large amount of resources and effort allocated to building ML-based systems, those efforts have often been throttled by the lack of reliable labelled data. Although building and refining datasets has recently gained more attention, relevant resources have remained limited for teams working on such problems. In this article, we shared our experience and provided practical tips to help anyone design and tweak data annotation projects according to their use cases. Regardless of the role you play in your team, the listed questions and steps will guide you through the process and hopefully make your work more efficient!


Follow us on