
Problem Statement
Imagine, out of thousands of accommodations that match a user search, you have to select the “best” 25 to show to the user. Which ones would you show- the ones you know perform well or ones that have never been shown before, so that you can discover new high-potential accommodations? In the Data Science world, this is known as exploitation (continue doing what works well) versus exploration (try something new to discover hidden potential) problem and is often explained using the well-known multi-armed bandit problem. The objective of the problem is to divide a fixed number of resources between competing choices to maximize their expected gains, given that the properties of each choice are not fully known at the time of allocation.
In the context of ranking accommodations in trivago, the fundamental issue we are trying to solve is selecting the optimal order from the millions of accommodations to show to the user, where optimal means relevant to the end user. Exploitation, in this case, means showing users accommodations that have historically performed well. Exploration means showing accommodations that have never been shown to the user, with the hope of finding those that will perform better than those currently shown. The explore-exploit problem is particularly challenging in this case because the number of accommodations that users never see is much larger than those seen by the user at any given time (also known as the ‘cold start problem’).
To understand why exploration can be beneficial, let’s take the point of view of three players involved: our users, our advertisers, and trivago:
- Users will benefit from a ranking algorithm that explores unknown inventory in the long run compared to one that just exploits known good accommodations as it would eventually find better items in the previously unexplored inventory.
- Advertisers rely on conversion data to optimize their bids. Exposing users to a wider range of their inventory will yield more diverse conversion data, allowing advertisers to bid more efficiently. This is especially crucial for new inventory.
- As for trivago, we act as an agent between our users and our advertisers. Striking a good balance between exploration and exploitation for finding good items in the unexplored set would be good in the long run to maintain a healthy marketplace and continue offering our metasearch value proposition.
Objectives
With this dilemma at hand, we want to find the optimal way to explore unknown inventory. For any given exploration mechanism you need to consider three things: extent, cost and quality of exploration. In general, all three would be different for a particular exploration scheme, making comparisons difficult. So, the goal is to have an algorithm where the extent of exploration can be controlled for the trade-off between the cost and quality of exploration. In our case, one can think about:
- extent of exploration as increase in clickshare of accommodations that were not exposed before
- cost in terms of topline user and revenue metrics
- quality in terms of performance of newly exposed inventory.
Behind every result there is a great process
Over the course of two quarters, we focused on a pure iterative test and learn approach. We ran several A/B tests and used the output of the analyzed results to recommend the next test set up. We tested numerous approaches in parallel and looked into model and engineering complexity, cross test interactions, etc.. In this article, we focus only on one of the approaches.
Baseline
One of the features in the Ranking model is calculated using historical information on the performance of inventory over the course of a fixed set of days. The feature values distribution follows a beta-binomial model. We are currently exporting the mean of this distribution as a posterior and this default value sets the exploration level. This is not an optimized value, but rather just one reasonable value to use. A potential issue with such a scheme is that it is too greedy, purely exploiting well-performing accommodations in the model.
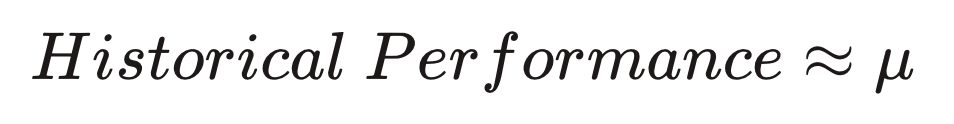
Step 1 (Naive approach)
Instead of choosing the expected performance of the accommodation, one can be optimistic about its performance instead. The less one knows about the accommodation, the higher its potential performance could be, whereas accommodations that are well known could not deviate very far from their historic performance. Optimism about the accommodation’s performance can be achieved by using the mean plus a fraction of the standard deviation(σ) of the posterior. This would favor items with low impressions since they would have larger standard deviations. A lambda (λ) parameter is added here to control the strength of exploration.
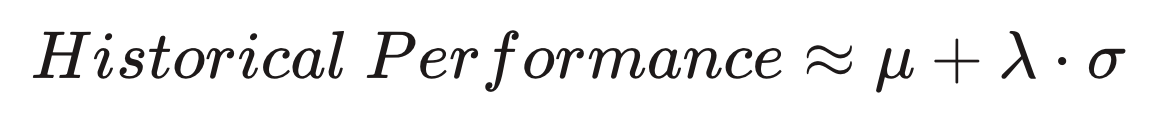
We call this approach “naive” since it only depends on the number of impressions and clicks the accommodation got in the past.
Step 2 … Step N (Model-based approach)
A problem with the previous approach is its inability to distinguish accommodations with the same level of exposure. For example, there is a very large number of accommodations that are never impressed, and it would not be efficient to cycle through them randomly. In order to explore smarter, we can use information about the inventory we know a lot about in order to identify which accommodations in the unknown pool are most promising.
In practice, we train a model to predict the performance of an accommodation given certain features of this accommodation. We use the historical performance of high-impression inventory to train the model and obtain a prediction function f(item features). This function is then used on low impression inventory to find suitable candidates for future exposure. Items with a high model score but low/no historical impressions would benefit the most in this scheme.
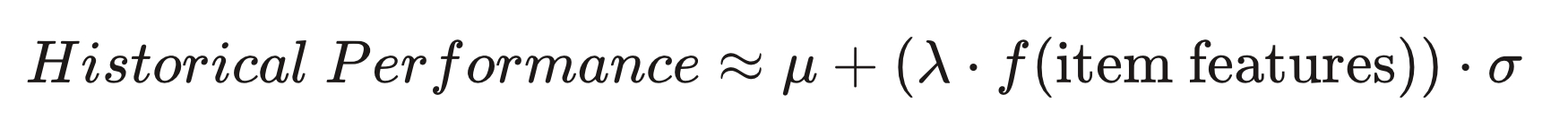
Some data mining techniques used in the course of actions included but were not limited to: EDA (exploratory data analysis), feature engineering, data preprocessing (cleaning and imputing for missing feature values), standardization/normalization of model outputs, etc.
Results
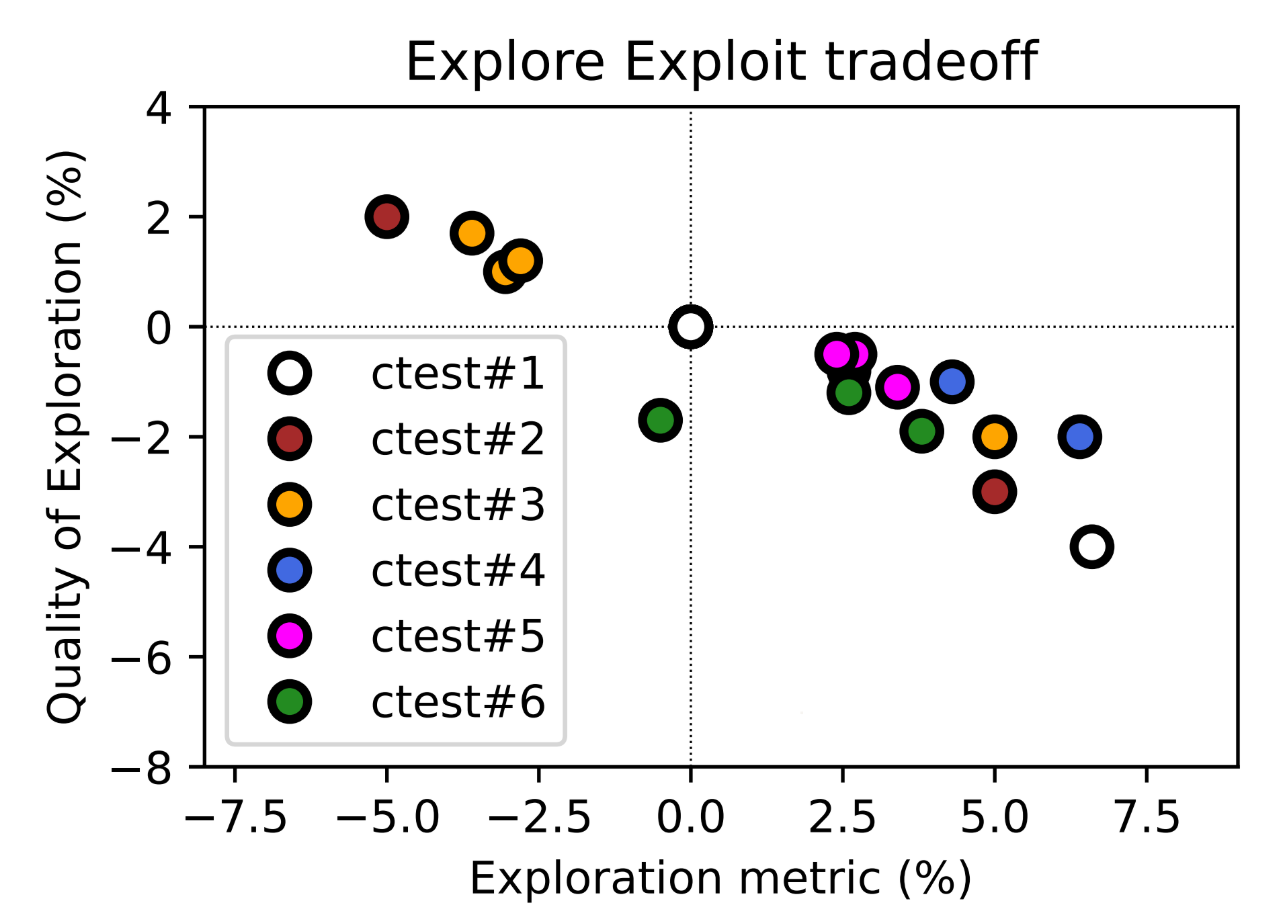
The chart above illustrates the trade-off between extent and quality of exploration for the experiments we ran. Negative exploration in this case means we are exploiting already exposed inventory. Test variants of the same color illustrate different levels of exploration for a particular test. For example, if we look at the two white dots for ctest#1, we can see that more exploration (dot on the right) led to a drop in quality. Ideally, we want to be on the upper right as much as possible, which would mean a high exploration rate with high performance of the newly exposed accommodations. If one connects the Pareto Front, test variants on the line represent the best possible trade-off, while tests below that line offer suboptimal trade-offs.
Key Learnings
- Key Learning 1: We increase the user value by exposing a higher share of high quality unexplored inventory at no short term revenue cost
The Explore-Exploit dilemma comes with a trade-off of impressing unexplored inventory at a specific cost for the users and advertisers, and we seem to have achieved the “golden mean” in our pursuit of optimizing value for our users, advertisers, and trivago overall.
- Key Learning 2: There was no significant shift in advertiser clickshares due to the exploration mechanism
Clickshares for advertisers remained the same as a result of the accepted mechanism, meaning by exploring low-impressed inventory, we did not shift clicks towards a particular advertiser.
- Key Learning 3: Lambda acts as a good parameter for controlling the extent of exploration
As mentioned in the beginning of the article, having control over the level of exploration was one of the objectives. Through a lambda parameter we were able to measure a Pareto Front between the level of exploration and our topline metrics. In case we decide to iterate over this project, this tunable parameter will help us to easily setup pseudo-control variants for testing new A/B experiments.
- Key Learning 4: Models do not always do what you expect them to do
By simply feeding a set of features into a black box model, we cannot expect the model to perform exploration- it is important to understand how the outputs from the model translate into the metrics we are trying to measure with these experiments. That being said, some models had negative exploration or had worse quality compared to the naive approach.
The Status Quo and Next Steps
The status quo as of today is that we have the exploration mechanism up and running in production within the framework of our accommodation ranking model. We have documented and compiled learnings from the A/B experiments that we ran throughout two quarters. In addition, we improved the code base for our Spark library and auxiliary tooling.
Furthermore, we have created monitoring dashboards to stay on top of trends of the exploration levels in our model over time. Here, a specific range of charts include monitoring of:
- what the distribution of the values of the features used in the model looks like
- how exploration cost metrics change
- how exploration quality metrics change
This along with the learnings we have gained from our experiments will serve as a starting point when we decide to tackle the exploration problem in even greater detail.
Summary
For an accommodation metasearch, like trivago, with a vast inventory to compare across and rank accordingly, the Explore Exploit dilemma is a very challenging issue. The challenge can be overcome by combining classical approaches to exploration with model based approaches in order to identify the most promising inventory in the unknown pool systematically.

Follow us on