
Data validation is an essential step in any data processing pipeline, as it ensures the integrity and accuracy of the data to be used across all subsequent processing steps. Great Expectations (GX) is an open-source framework that provides a flexible and efficient way to perform data validation, allowing data scientists and analysts to quickly identify and correct any issues with their data. In this article, we share our experience implementing Great Expectations for data validation in our Hadoop environment, and our take on its benefits and limitations.
Great Expectations Overview
Terms used in this article
Great Expectations has a lot of features to support data validations. To simplify, we would explain the terms relevant to this article.
Expectation: a defined criteria that specifies what the data should look like. Great Expectations has a lot of built-in expectations that can be easily used, the list can be found here. We can also customize our own expectations. The following is an example of an expectation that expects the minimum value in a column to be within a certain range:
expectation_type: expect_column_min_to_be_between
column: 'income'
min_value: 10000
max_value: 50000Expectation Suite: a collection of expectations that are defined and merged together into JSON or YAML files.
Data Context: a configuration in which data source and other components are defined.
Checkpoint: the abstraction to bundle our defined Expectations Suites to our defined Data (Batch).
Validation Result: an object generated when data is validated against an Expectation or Expectation Suite.
Data Docs: a feature of Great Expectations that generates a human-readable static HTML page of the validation results.
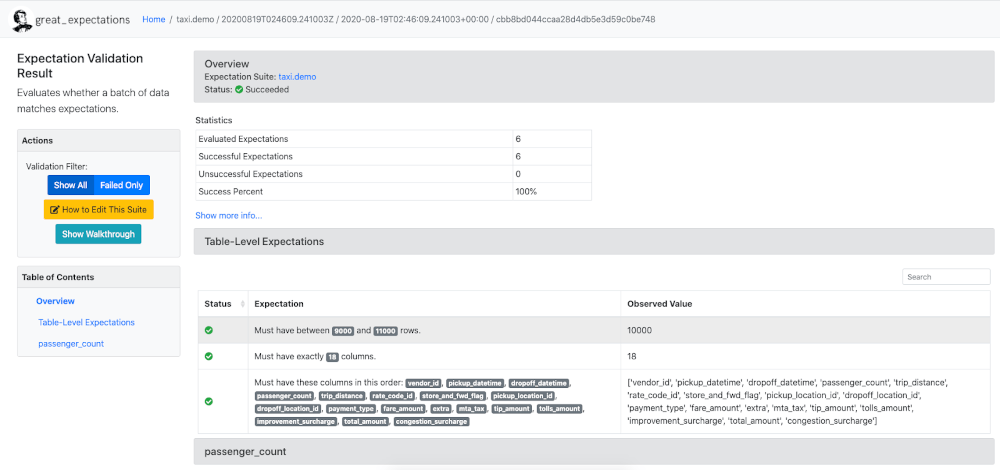
Use Case: Implementing Great Expectations in Hadoop Environment
Our stack
We wanted to run the data validation as part of our automated data pipeline in the Hadoop ecosystem, and since GX is a Python library, we wanted to run GX as a PySpark job as part of our Oozie workflow.
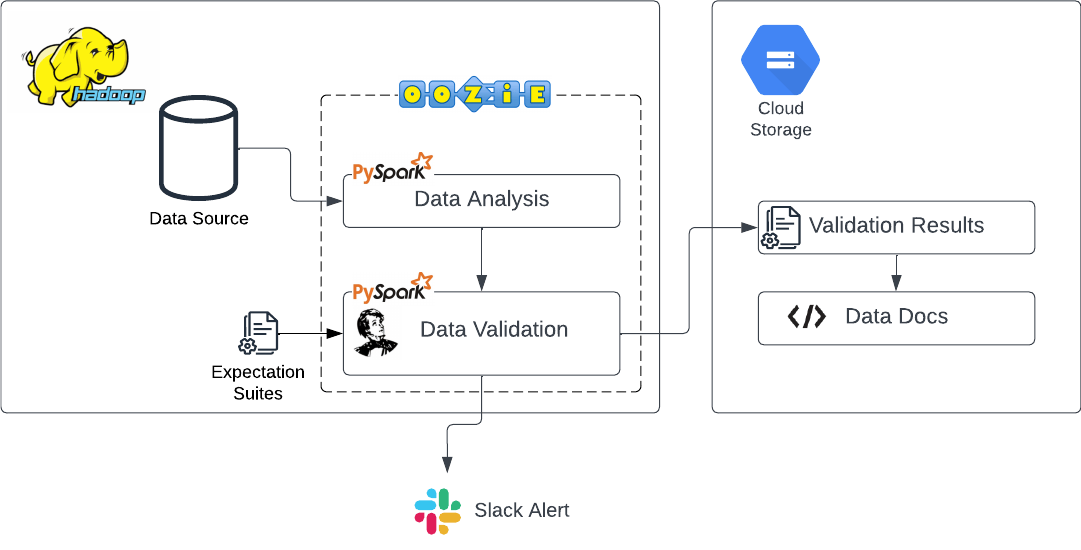
Setting up the Data Context
When we implemented Great Expectations in our Hadoop Environment, it was not an everyday use case. By default, everything in the Great Expectations deployment framework are expressed in a directory structure within a great_expectations/ folder within your version control system. This approach is not possible in Hadoop Distributed File System (HDFS). So, instead of using the default setup, we configured our Data Context in code. We configured the Expectation Store, where the Expectation Suites are placed, to a local path; this makes it easier for us to change the corresponding expectations from our repository. We put every other context generated by GX such as the Checkpoint Store and the Validation Store in the Cloud storage since we would not need to make changes to these files.
Using SimpleCheckPoint to run default actions
When creating the checkpoint to run our validation, we can use SimpleCheckpoint instead of Checkpoint in the class_name definition. SimpleCheckpoint is a built-in class that can be used to simplify the Checkpoint configuration. More information about this can be seen here. SimpleCheckpoint provides a basic set of actions - store Validation Result, store Evaluation Parameters, update Data Docs, and optionally, send a Slack notification - allowing you to omit an action_list from your configuration and at runtime. We use SimpleCheckpoint to run our validation because it already provides us the set of actions needed for our use case. Alternatively, we also use the Checkpoint class to customize our own set of actions.
Customizing Data Docs to Manage Validation Results
Great Expectations already has a great feature to document the validation results as a Data Docs site. Filesystem-hosted Data Docs are configured by default for Great Expectations deployments and are created using great_expectations init, but we can change the configuration to use Cloud storage and customize a separate Data Docs site for each team. In this case, we made our own UI to integrate the Data Docs sites for several teams and users, making it easier to evaluate the validation results.
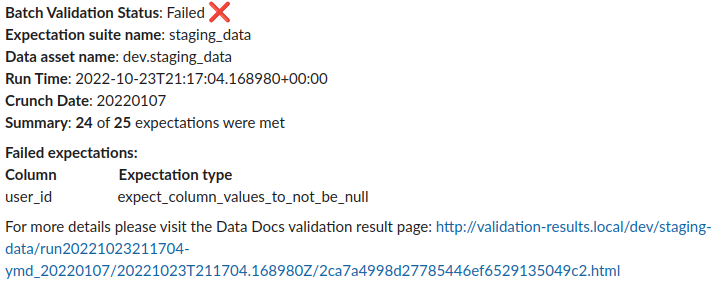
Custom Slack Notification
By default, SimpleCheckPoint has the option to send a Slack notification for every Checkpoint run. But we wanted to have more visibility and simplicity, so we customized the message by using the CheckpointResult object generated by run_checkpoint in Python. The following image shows how we customize our Slack notification message.
Pros and Cons
With the implementation of Great Expectations as part of our data pipeline, we found many benefits, but also some limitations.
The positive takeaways
Great Expectations provides some convenient data quality features useful in the big-data lifecycle. While we have a broad definition of “data quality”, this tool covers the most important parts for us. Importantly, GX ships with several useful definitions out of the box, which are especially useful because they considered the simple cases that we might have otherwise overlooked, and were easy to tune to our needs.
In some cases, we need to ensure that columns meet certain criteria, like containing less than 4% of values being NULL, or only 2% containing duplicate records; this allows us to maintain high data quality in cases where 100% conformance is either impossible or unnecessary due to technical or business reasons. In other cases where there is no strict standard for what counts as an acceptable value, we have received alerts which made us realize that our rules were too strict and must be adjusted accordingly. By adjusting the “Expectations” (or alerting rules) in our project’s Expectations Suite, we can adjust our data validation to suit our needs.
From these cases, we can see that GX was a fitting addition to our data pipelines. Many of these situations were small enough to not be picked up by our existing anomaly detection tools, but over time would have had a negative impact on our data quality.
Some (minor) limitations
One of the limitations that we found in Great Expectations is the kind of data validation that can be done. For example, GX does not have any built-in tools for more advanced data validation techniques such as statistical analysis or machine learning.
Summary
Great Expectations is a tool for validating data pipelines and data quality. It can perform a variety of data validation tasks, including checking for missing or null values, checking for correct data types, and verifying that data meets certain criteria (such as being within a certain range). Great Expectations also has features for comparing data to expected results, generating reports and alerts for data issues, and tracking the history of data changes.
On benefits, we found that GX has great built-in features for data quality, adds great value to our data lifecycle, the expectations definitions are easy to modify, and it’s very customizable and can be adjusted to our atypical stack. The limitations we observed are that it does not have any built-in tools for more advanced data validation techniques, and it does not have great documentation for certain production implementations. Overall, Great Expectations is useful to help ensure data quality, and for identifying and addressing any issues that may arise during the data pipeline process.

Follow us on