
TL;DR
During the development of customer-facing applications, time is crucial, especially when it comes to testing and analyzing changes before accepting them in production. This blog post explores how we developed a Java-based reactive tool to simulate production requests, that allows us to have quicker hints about the effects of changes introduced and be more confident about the hypotheses that are formulated. As a long term vision, we wish to significantly reduce the A/B testing time and ensure seamless transitions.
Motivation
At trivago, our goal is to provide our users with the best possible experience when searching for accommodations. We understand that when users embark on their travel journey, they want to find the perfect place to stay at the best prices available. This is where the Marketplace unit comes into play.
Our dedicated Ranking and Auction teams are responsible for ensuring that our users are presented with a curated selection of accommodations that match their preferences and requirements. We leverage advanced algorithms and data-driven insights to identify the ideal accommodations with the most competitive prices.
To achieve this, we continuously iterate and improve our services, which often involve making changes to the underlying algorithms and systems by testing various hypotheses. Consider the scenario where we aim to validate a hypothesis that accommodations closer to the city center are more preferred by our users. To test this hypothesis, we initiate an A/B test that involves two variants: a control group and a test group. In the control group, we present users with an accommodation list sorted based on the relevance score, following our established algorithm. However, in the test group, we prioritize accommodations that are in closer proximity to the city center.
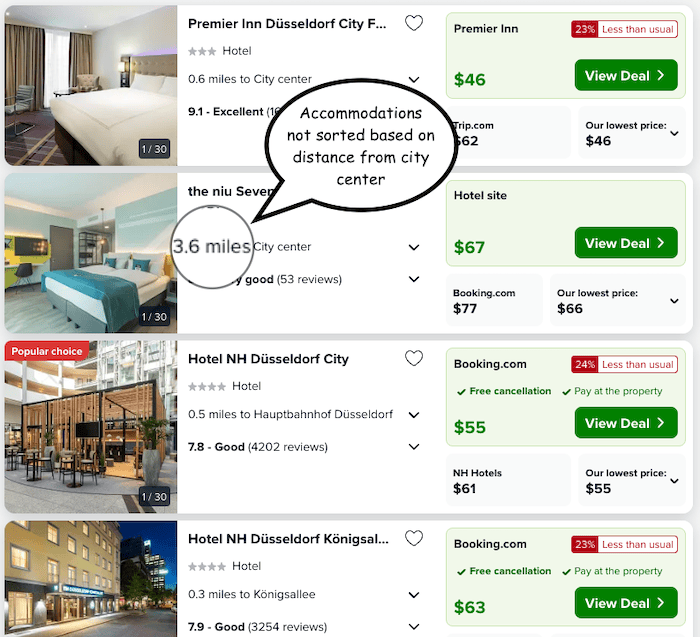 Control result: Accommodations sorted based on our current algorithm.
Control result: Accommodations sorted based on our current algorithm.
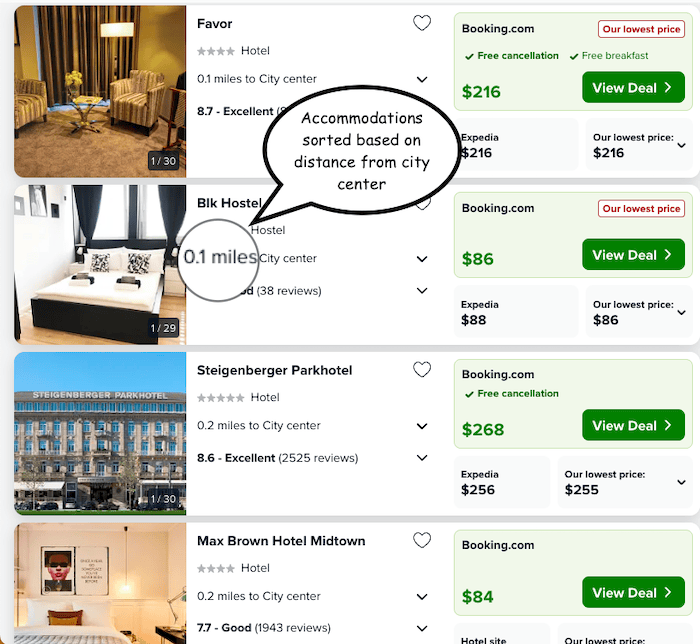 Test result: Accommodations sorted based on proximity to the city center.
Test result: Accommodations sorted based on proximity to the city center.
By comparing the outcomes of the control and test groups, we can determine whether the hypothesis holds true and if the proximity-based sorting yields improvements in key metrics. However, conducting A/B tests of this magnitude necessitates gathering a substantial amount of data from user visits. To ensure statistical significance and confidently interpret the results, we need millions of user visits, which can span several weeks to accumulate. This lengthy testing period introduces delays and slower innovation, hindering our ability to swiftly iterate and implement improvements. Moreover, an experiment can also turn out to be negative and incur revenue losses. While we aim to validate our hypotheses and introduce enhancements, we recognize the inherent risks associated with experimentations.
We wanted to improve our testing process by having methods to gather initial feedback in a fast and cheap manner. Ultimately, we want to find a solution that would allow us to expedite the testing process without compromising the quality.
What do we want to simulate?
Before delving into the details of our innovative simulation service, it’s essential to grasp the existing system that it aims to simulate. The Result List Composition (RLC) service is one of the most crucial services in Ranking and Auction teams. It takes various inputs, including metadata containing a list of experiments, and a collection of accommodations with deals sourced from different advertisers such as hotel chains and OTAs. RLC’s algorithm proceeds to select the best deal for each accommodation and subsequently organizes and returns the most relevant accommodations to the user.

The simulation service
In order to prove the value of simulating experiments, we built the simulation service, a Java application that replays a sample of production requests. The application allows us to reproduce the “control” result from RLC and also enable modifications inside the service via feature flags in separate requests. As we wanted our simulations to be flexible, it is possible to simulate different modifications independently within the same run.
After executing each of the requests, the simulation service collects an enriched version of the responses provided by RLC, which contains additional information gathered during the execution of a request that is helpful for analysis. In the last step, the application produces raw results into a Kafka topic, which are ultimately persisted in Hadoop, the data lake that is commonly used throughout the company.
The process of simulating experiments using this application is as follows:
- An algorithm change is implemented inside the application behind a feature flag. This can either already exist in the service or implemented in a feature branch, for which a preview instance is spun up.
- The simulation is executed with specific parameters, such as the dates of the sampled requests that should be replayed and the feature flags to enable in each of the simulation variants.
- A simulation is concluded once all the selected requests are replayed. After this, an analysis can be carried out with the results produced.
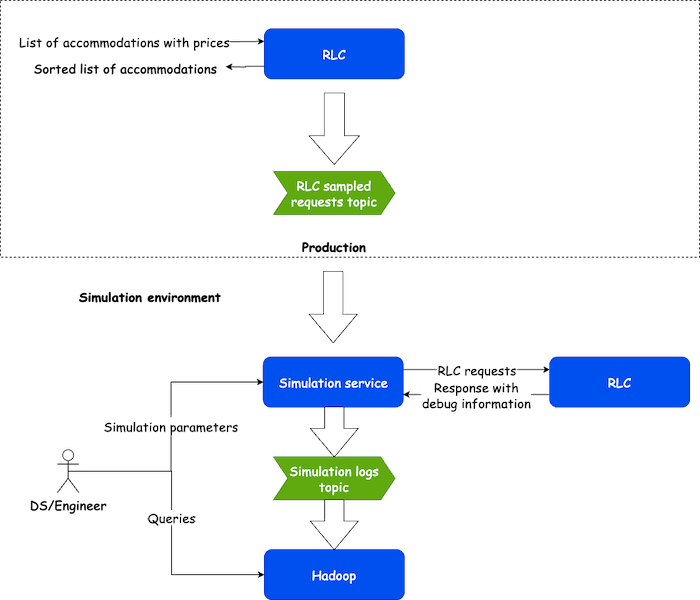
As we designed and built the solution described, we had several considerations in mind:
- The solution shouldn’t interfere with production traffic (which could possibly affect the experience of visitors of the site). Therefore, we run the tool in a separate environment for development purposes.
- We should develop the tool with cost-effectiveness in mind. Therefore, we store the large amount of newly created data just for a time window that is sufficient for analyzing it.
- Even though the Java application is not a customer-facing application, it was developed with performance considerations in mind to allow faster innovation. Therefore, it was developed using Reactor, a reactive framework that the team was already familiar with and has collected profound experience in the past. Executing the requests in a non-blocking manner was crucial to handle the additional latency introduced by producing enriched results inside RLC. This approach allowed us to increase the amount of simultaneous requests while having a better resource consumption inside the simulation service.
- We were aware that the quality of the requests sample would deeply influence the results of the simulation. Due to this, we sample requests from our live services randomly and aggregate them from all country platforms served by the website, which is not trivial as it involves combining streams from different datacenter regions. This is also beneficial for users who are only interested in the effects in certain markets or certain type of traffic.
- Users of the simulation tool would benefit from having feedback during the execution of simulations. For this reason, the tool produces periodic updates and statistics to a Kafka topic. This information is indexed and visualized inside the Elastic stack. It has the additional benefit of providing insights of the tool usage.
- Lastly, as we also focused on making the solution easy to use in order to increase the adoption within the team, a client tool was created. This tool written in Python, a language widely used within data teams, provided the query heavy lifting of commonly used metrics computed out of the simulation results.
Revisiting the proximity to city center hypothesis we discussed earlier, we can leverage the simulation service to have quicker iterations and validations of the new algorithm. By replaying old traffic, we can measure the effect of the changes introduces to the result list, the dynamics of certain positions and understand the potential revenue impact it might have. Although this gives an advantage, there is still something that is not solved, the tool doesn’t simulate user click behavior, for which an A/B test would still be beneficial once we have decided which algorithm configuration to test.
Conclusion
The introduction of our Java-based reactive simulation service has revolutionized the way we test and analyze our changes before deploying them to production. By simulating requests and optimizing the testing process, we are able to iterate faster. It allows us to consider more alternatives in our tests and choose the optimal one, something that would normally extend the testing period with traditional A/B testing.
The architecture of our simulation service, with its reactive codebase, ensures efficient processing and seamless handling of large amounts of data. The integration with Kafka and Kibana provides comprehensive progress tracking, empowering us to monitor simulations and collect valuable insights for analysis.
The road of accelerating our experimentation efforts through simulation hasn’t ended here. As the new tool has proved to be useful for the team and its adoption has increased, we’ll be addressing new points. One of them is scalability, since we want to enable multiple team members to run simulations simultaneously and in a faster way.


Follow us on