
How we migrated our images infrastructure to Google Cloud
When we think about migration, we usually imagine moving something or someone from one place to another. Doing so has inherent complexities, which can exponentially grow when migrating a software solution. In this article, we’re sharing our experience on how we migrated all our image-related infrastructure to GCP (Google Cloud Platform) from a combination of AWS (Amazon Web Services) and our Data Centre.
- Context
- Initial setup
- Previous Migration Efforts
- Final Round: Migrate to GCP (again!)
- Going Live
- Challenges
- Learnings
- Summary
Context
trivago gets images from multiple sources; the vast majority come from partners and hoteliers. Partners can be either OTAs (such as Expedia or Booking.com), Hotel Chains (such as Hilton and Premier Inn), or content-only providers who (as the name suggests) provide only content (without prices) along with images.
These images need to go through a drastic amount of filtering, evaluations, and re-organizing before we deliver them to our users. Therefore we have a lot of data pipelines in place to ensure the best quality of the images users see.
One such data pipeline is the Image Gallery pipeline which selects the best images for the users, showing the highlight of the corresponding hotel with a custom selection logic based on various parameters such as the contents of the image (bedroom, bathroom, etc.) and its quality. We have a separate pipeline performing the image tagging using an in-house Machine Learning model to detect the contents of the images, and also a custom image-processing logic to extract the quality of the images. Several more pipelines are running to assist this process by extracting the parameters above.
The number of different pipelines and their requirements have grown over the years and there have been several attempts to migrate them into the cloud. The outcome was a sophisticated, distributed, and unoptimized set of pipelines running across multiple deployment environments. Therefore a “lift-and-shift” approach to migrate them was not an option, mostly because many of the pipelines were heavily dependent on the features provided by each vendor or the technology. it was evident that we needed to re-design our pipelines to make them more efficient and extendable in a single cloud environment to reduce the development time and operational costs.
Initial setup
When we started processing images, we had a simple setup due to the requirements also being quite simple. We had a few hundred hoteliers and partners providing images now and then, and we didn’t need a complex system to process them. We had an in-house PHP framework and most of our systems including the Image API were based on that. We had RabbitMQ to communicate between these services and some workers running in our Data Centre to process them. All these pipelines shared a single database and it was sufficient at that time to hold everything we had.

Previous Migration Efforts
Round 1: Migration to AWS
We have some prior experience in migrating our image infrastructure in trivago. Our first migration from our on-prem infrastructure to AWS occurred in 2018. The main driving force for moving our infrastructure to the cloud was to simplify the business requirements and have an easier infrastructure to maintain. Images pipelines were planned to be migrated to AWS (Amazon Web Services).
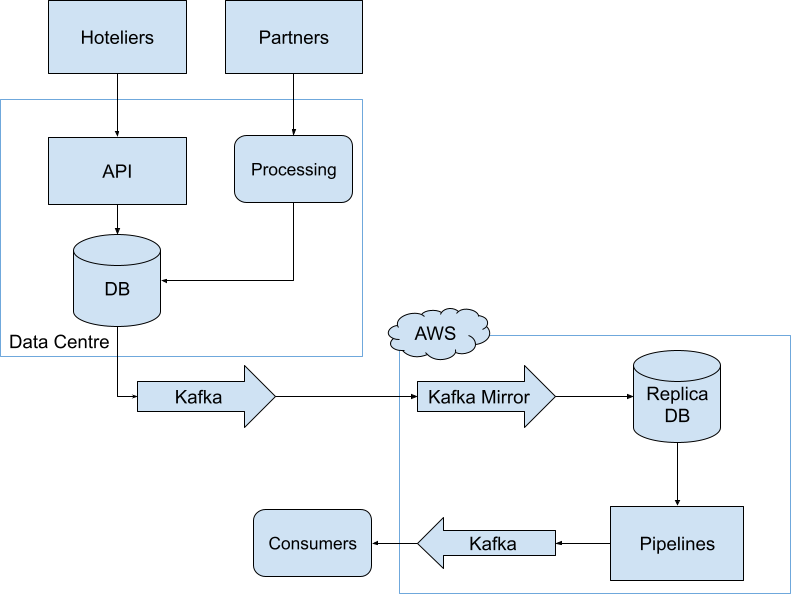
Now our input (from hoteliers and partners) has grown tremendously, from around 100 million to almost 150 million over the last couple of years. The number of different pipelines using the same database has also increased, making the database bloated. Therefore, we couldn’t do a clean migration to AWS because many other teams still used the database as their source of truth. For instance, all the information about the hotels was still written to the database and we needed that information to generate the Main Images (the thumbnail image for a hotel) and the image galleries. Of course, each responsible team tried their best to balance the feature implementation, bug fixing, and migration. With the hope that they will migrate soon, we started migrating our consumer pipelines to AWS.
We started injecting all our image files into AWS S3 due to its high availability and made our new pipelines to use those. After over a year, we migrated all our consumer pipelines to AWS which had inputs from our Data Centre via Kafka topics. We replicated the images-related portion of the database in AWS. We built our user-facing pipelines on AWS by reading our replicated database. This is also the point where we moved away from PHP in favor of Python because most of the cloud providers heavily supported it.
We also introduced a new ID generation pipeline for images to unify images coming from different sources. These IDs could be used to uniquely identify any image at any point of the processing. However, we still had to maintain a mapping between the old and the new image IDs because there still were some teams using the old IDs. Then it became more difficult to implement new features because we had to determine the type of IDs we should consider.
When the migration was (partially) done, we had three parts to maintain: Data Centre pipelines, Replication pipelines (Kafka and Debezium), and Consumer pipelines (i.e. Image Gallery).
Round 2: Migrating to GCP
When we decided to streamline our Cloud usage and move everything to a limited number of Cloud providers, every team using alternative cloud providers had to move their pipelines to GCP (Google Cloud Platform). Even though this decision made sense from a strategic business point of view, now we had a lot more complex pipelines to migrate.
We could have started from the same place as the previous AWS migration, however, many things had changed by then: In both the people and responsible teams, technological expertise, new requirements, amount of data, and many more! One positive fact was that we had gained an excellent understanding of Cloud technologies, their best practices, big data processing frameworks such as Apache Spark (AWS Glue), and an overall understanding of our requirements which were slowly getting stable. In addition, we slowly moved towards Apache Beam which is available on GCP as Dataflow: a fully managed Apache Beam service.
However, there were several challenges in migrating from AWS to GCP which meant we were not able to immediately do a full migration and instead took an incremental approach. The biggest one is that all our image files were still on AWS and it would’ve cost us a huge amount of money to migrate them to GCP in one go. The next was that all our pipelines were using S3 directory paths to read the images (either directly or through our CDN). Last but not least, it was nearly impossible for us to migrate our Replica Database along with the newly generated IDs. As we were already keeping a mapping between our old and new image IDs, we didn’t want to create a new set of image IDs.
Therefore, we decided to move the processing pipelines to GCP while keeping the image files and the ID generation pipelines still on AWS.
After a decade of modifications and multiple migration efforts, the image infrastructure was spread across multiple technologies, architecture patterns, and even three different deployment environments.

This was not only difficult to maintain, but also cumbersome to debug any issues as the components were distributed.
What went wrong?
Over the years, the image infrastructure has been through a lot of changes both in technologies and requirements (including the amount of data it should handle). Several people were a part of the initial migration efforts and they already knew what wouldn’t work. Even though many of those reasons were inevitable, now we had a better understanding of our requirements, all the edge cases, and all the not-so-good decisions that we made. In the subsections below we will explore the three key learnings that we obtained during the migration process.
01. Starting from the consumer pipelines
In retrospect, one of the biggest mistakes we made was to start each of the migration efforts from the consumer pipelines. This was mainly because many other teams were still using the database and the provided API, and we didn’t want to introduce breaking changes for these consumers. However, this approach was a less optimal route for a migration project and forced us to go with a more distributed solution with a lot of overhead.
As you have seen in the architecture diagram, the database was the heart of all our pipelines. If we had started the migration from moving it to the Cloud, the migration process would have been more complex because we wouldn’t see any output until all our data pipelines were migrated, but it would have been cleaner and much more efficient.
02. Not taking enough time to re-evaluate
Over the years, as with any software solution, the requirements for our image pipelines have evolved. What we couldn’t do (mostly due to timeline limitations) was to pause and re-evaluate our requirements from both a business and technical perspective. In addition, we did not reflect on the existing design(s) before jumping directly into the migration.
Focusing solely on immediate needs like bug fixes, new features, or migrations, can create a complex and inefficient system over time. Instead, we should have taken a step back and considered a complete redesign – a holistic architecture. This could have involved merging components for a more unified system. Think of it as rebuilding the house with a modern, efficient layout. By doing this, we could have addressed the inherent flaws of the decade-old architecture, resulting in a simpler and more reliable system.
Focusing solely on immediate needs (such as fixing a bug, adding a new feature/component, or even doing a migration) would make the system more complex and inefficient over time. At that point, instead of migrating different components to a cloud environment and trying to make them work with the old paradigm, we should have considered a more holistic architecture and tried to consolidate different components into a more cohesive approach. This would have enabled us to fix a lot of flaws in the old architecture which was designed over a decade ago and made the system considerably simpler and more robust.
03. Non-optimal architectural patterns
There are so many architectural design patterns for different use cases, and many of them are widely used by tech giants in the industry. However, this does not mean that they would perfectly fit our particular use cases. Initially, we were quite new to the cloud technologies and we had to learn a lot about cloud architecture patterns from different sources. The mistake we made was to follow some of those patterns without an in-depth analysis of whether they would fit our needs.
One such example is the usage of Kinesis → Lambda was quite popular back then and also promoted well by different companies. However, trying to fit our data pipelines into it slowed us down and tremendously increased the cloud cost. We could have invested more time in trying Map-Reduce technologies such as Apache Spark or Apache Beam.
These were some of the significant mistakes (or rather the things that should have been done) during the last couple of migration efforts.
Every organization goes through various types of changes and ours is no different. A little after we finished our last migration, we had an organizational change and got a dedicated team (again) to focus on images. Many teams had also finalized their migration and were (almost) already on GCP. When the topic of decommissioning legacy infrastructure resurfaced, we had an opportunity to make things right!
Final Round: Migrate to GCP (again!)
It was mid-2022 and a couple of months after a small organizational change. We had to decide how to proceed with our old infrastructure in our Data Centre and AWS. They were working fine, but it was difficult to make changes mainly because of the heavily outdated dependencies and knowledge gap.
Now, we had a dedicated team only for image-related topics, and we had a choice! We could have either kept on maintaining the old infrastructure and implemented new features on top of it, or we could have done things differently and re-designed everything. Yes, you were right: we did the latter.
This was not merely another software migration project, but an entire redesign of the flow of images in trivago. Everything from the sourcing to the delivery of images would be affected by this migration. So we needed more people to work on this to make things faster, and we combined two independent (yet closely related) teams to work as one. This also brought an entirely different dynamic to the team because now we had two Project Managers, two Engineering Leads, and several Software Engineers from two teams. We agreed on the responsibilities of each person and best practices to make everything smooth.
We started the project by listing all our stakeholders, their requirements and wishes, and existing pipelines along with their limitations and conceptually ordering them according to the data flow. This process took us more than a month to complete. Then we tried to break the flow into components so it’s much easier to design and implement asynchronously.
The first one we picked to design was the API, unlike during the previous attempts. This component is used by two other products which were developed by two different teams. When we migrate our API, these teams also have to adjust their products accordingly. With additional requirements and addressing existing limitations, we couldn’t proceed with the existing API schema. The first thing we did was to agree on an API Schema (in Swagger) with these teams and arrange frequent alignments to ensure everything is done accordingly. Having an API Schema enabled different teams to adjust their products without waiting for our API to be deployed.
After considering several options for a database solution, we went along with a managed MySQL system to handle the enormous amount of relational data. We also designed the tables to handle our image ID generation which was previously handled by a separate pipeline. That resulted in dropping a very expensive pipeline that was running on AWS for quite a long time. Then we carefully normalized our tables to get the best out of table indexes which made querying efficient.
Next, we started implementing the image ingestion from our partners. We usually get millions of images at once from many partners from scheduled imports, and we needed a proper mechanism to handle them. That’s when we realized a batch-processing Apache Beam pipeline would be a good choice to bring all the new images into our system. With a unified image ID degeneration process, it was easy to detect duplicates imported from similar URLs and even different partners. These images are stored in GCS (Google Cloud Storage) and exposed through our CDN setup. It also enabled us to easily deactivate images across multiple hotels when different hotels or partners share their image inventory.
Finally, we had several discussions with our consumer teams to understand their requirements and pain points with the existing setup. It enabled us to agree on schemas for our Kafka topics, and they could also start adjusting their components to consume our new data. While they were getting ready, we could independently implement our data processing pipelines for Image Gallery and Main Image calculation. We also didn’t forget to keep them informed about the progress and any changes to the schemas.
After a little more than a year, we finally finished implementing all the necessary components with a set of highly efficient data pipelines.

In the end, this ended up not being a migration of existing pipelines, but rather a re-design and a re-implementation of the requirements.
Going Live
We are a backend team and it’s a little bit different when we want to go live with a project. Since this is a migration project, the minimal requirement would be that the users won’t see any difference in their experience using trivago. With the optimized design and adherence to the new requirements, hopefully, we will have positive feedback from the users.
We have a sophisticated A-B Testing framework at trivago for testing a feature (in this case an entirely new infrastructure) to see if that affects the user behavior. The goal was to enable this type of test and see if we saw any positive (or at least neutral) impact.
For this, we should have all our pipelines up and running. To make things complex, we would also get input from different types of users: hoteliers. They can also upload and manage images that they would like to show on trivago and that’s done via a separate tool called trivago Business Studio. Therefore, going live also meant allowing the hoteliers to use our new infrastructure and being able to see the changes on trivago.
Since we are the bridge between hoteliers and the trivago frontends, we decided to deploy all our pipelines first and then ask the corresponding teams to switch to our new infrastructure. Before deploying everything on production, we deployed each of our pipelines on our staging environment and asked the corresponding teams to connect their staging environments to that. Then the teams responsible for the Image Suite (the internal admin tool for images, implemented by a separate team), trivago Business Studio, and GraphQL (which is used by all trivago products to serve data to users) started using our new API and the Kafka topics.
We tested everything on stage and everything was working as expected, mostly! We still had to fine-tune some settings on our CDN and some other places to get everything smoothly running. We were quite surprised to see the performance of our new infrastructure, which could handle a whole bunch of data faster than the old one. For instance, when a hotelier changes the Main Image of their hotel, it only takes a few seconds for the change to be shown on trivago compared to around a day in our previous AWS-based infrastructure.
Testing the stage pipelines for a couple of weeks enabled us to fix all the small issues that we and our stakeholders saw. Finally, we were ready to go live!
We did the production deployments in stages because we wanted to see the impact of different components on the user experience.
First, we went live with our API which was used by the internal admin tool (Image Suite) and the Business Studio, with the expectation that the changes wouldn’t be reflected on trivago for some time until we went live with all the products.
Then we went live on production with our Main Images pipeline as it was one of the most critical items for a hotel and an entry point to the hotel details on our platform. After running the test for a couple of weeks and seeing the positive results, we accepted the new Main Images infrastructure!
Finally, we prepared for the Image Gallery pipeline to go live. It needed more effort not only because it had more supporting components, but also because it had more images to show. We even had to quickly implement a cache warmup component to bring the images into our CDN cache to avoid any deviations from the optimal user experience in the control group which was still using the old infrastructure.
A couple of more weeks later, we had all our pipelines live on production serving millions of users with visual information helping them to book the best hotel for their next adventure!
Challenges
This was one of the biggest migration projects we ever had over the recent years so it was not free from challenges.
Individual Responsibilities
As mentioned before, we combined two engineering teams to complete the migration and it made things truly efficient. However, we faced a lot of discrepancies in the beginning about the way of working, redundant responsibilities, levels of expertise, and even personalities. For instance, having two engineering leads and two product managers on the same project was not the most efficient way of getting things done. So, we segregated the responsibilities for each of them in a way that they will have less overlap when it comes to decision-making. One such segregation was regarding the engineering leads: one agreed to take care of the existing pipelines and contribute to the migration as a developer while the other acted as the technical lead for the migration-related topics.
The way of working
Combining two teams for a short period to complete a software project sounds daunting especially when the strengths and weaknesses of the team are not properly identified. The two teams we combined had engineers from different backgrounds, different levels of experience, and even different personalities. Even though these team members were working under the same organizational structure and even shared the same lunch table, work can become more strained if the working dynamics don’t match.
With this in mind, we had a casual meeting at the very beginning of the formation to set the expectations where each member would tell what they expect from the team and what the team can expect from them. Even though this might sound simple, it made everyone comfortable with the new setup and collective goals.
We also created a detailed document for the “Way of Working” highlighting the tools & technologies, standards, testing strategies, pull request guidelines, and several more quality standards the team should follow. When these are agreed upon beforehand, friction between people will become less as everyone is following a documented process.
We also arranged a lot of team activities such as indoor and outdoor games, lunches and dinners, and some milestone celebrations to strengthen the personal bonds as well. This enabled the team to be more empathetic towards the others which is quite important to work as a team.
Things can still go sideways regardless of how much we plan. Whenever those situations occurred, we sat together as a team to evaluate it, agreed on a resolution, and updated the “Way of Working” document for our future reference.
Light only at the end of the tunnel
As explained above, this project was a massive re-designing and re-implementation of every aspect of the image infrastructure, which took one and a half years to complete. Because we were implementing everything in parallel with multiple stakeholders, we could only test each component and its limited functionalities independently. We had to solely rely on our tests to verify our functionalities and we weren’t able to do any end-to-end tests with every component running.
Therefore, it was a bit discouraging to the team to continue working without seeing an actual output for more than a year! We didn’t have a solution for this except mocking data for each component and trying to verify the outputs. It was really important to keep the team motivated and focused despite not seeing immediate outcomes and we had a lot of milestone celebrations, feature showcases, and shoutouts to ensure the members got the recognition they deserved.
Keeping track of everything
With the amount of different components we had to implement with different requirements from various stakeholders, we could have easily lost track of everything. However, our project managers made sure everything was properly documented. They documented all the requirements from the stakeholders for different projects, meeting notes of every design session and their outcomes along with the action items, and even the milestones and their timelines. Moreover, everyone in the team had an action item to read the documents and sign off. This slightly forced people to be aware of everything going on in the project.


Keeping everything well-documented is one of the top reasons this project was a success!
Key Learnings
This project helped us learn a lot of things throughout its course: not only about tech but also about people.
Plan ahead, properly
In most cases, due to many internal and external factors, we might have to do a “quick fix” when doing software projects. However, after looking back at our migration project, it’s evident that spending a little bit more time to understand the requirements properly before implementing can serve us better in the long run. If we hadn’t done so, we would have ended up with yet another unfinished migration.
It’s also important to keep the team motivated especially when the project lasts longer. Celebrating milestones, giving recognition to people, and planning everyone’s vacation accordingly helped a lot to keep a positive atmosphere in the team.
Mutual Agreements
Working with diverse people allows us to embrace their strengths and help them overcome their weaknesses. It also enables people to take charge of what they’re good at and help others to get on board. These differences should be identified as early as possible and agreed upon among the members. This also helps to have standards for our work and the processes that ultimately make our software better.
Document Everything
No one can remember everything they hear or tell. It’s especially true when someone has to switch between different types of work over a long period. That’s why documenting everything becomes a lifesaver. We won’t have to remember everything and can always refer to the documents to get more context. These documents also act as a reality check for the team to know whether they are doing the right thing.
Summary
Any type of software project can be difficult especially when it’s a massive migration project. We were able to move all our image infrastructure from multiple environments to GCP in one and a half years. The most important thing we learned is to plan properly and try our best to stick to it. If things change along the way, adhere to it and change the plan accordingly.
If we fail to plan, we plan to fail.

Follow us on