Concepts like separation of concerns, logic decoupling or dependency injection are things we developers have heard more than a couple of times. At trivago, the Android app is developed using the Model View ViewModel (MVVM) architecture, aiming for views as dumb as possible, leaving the decision making to the view models. This leads to an increased test coverage since testing logic in views is something we can’t do that easily.
What’s the problem?
MVVM is actually working pretty well, we are getting things out of the views and injecting all our dependencies in the view models so we can better test them in several scenarios. But, if we let the View Model (VM) take the responsibility for everything, it will grow to a non-desired size, which will lead to many new problems, like lacking scalability or testability. And all the beautiful concepts we named at the beginning would be far from reach.
As a concrete example, normally a VM would receive some user interaction from the view, it would update the view (showing a process indicator for example) and look into some session state or user preference, collect some info it needs and then decide how it is going to request some information from an API end point. After that it would try to answer some extra questions such as, am I connected to the internet? Do I have some cached data I could use? What do I do with the data I receive? Just pass it to the view or should I do some extra operation? As you can see, these are a lot of questions for just a poor VM.
What can we do about it?
Repositories to the rescue!
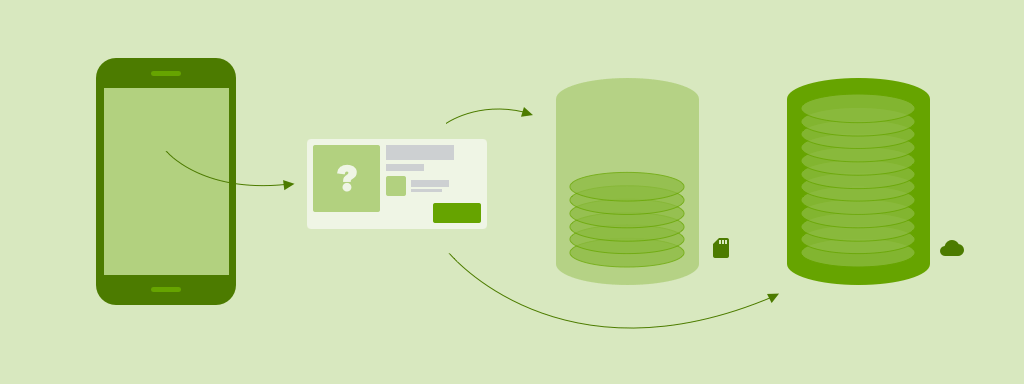
A repository is just a place where the VM can go to grab data. That is the interface the VM cares about. “I need the hotel with the id X”, and then the repository will take care of looking into its sources to deliver the right hotel. This goes a step further in the direction of [clean architecture] (https://8thlight.com/blog/uncle-bob/2012/08/13/the-clean-architecture.html).
So far so good, the repository will be the delivery man who brings the ordered food directly to the front door of the VM. Basically the repository will decide among an amount of data sources where to get the data from, and once it has done it, maybe store it in some other source.
How do we use it?
One handy example is a class we created for the trivago app, called MemoryNetworkRepository. As its name implies, this class will check if it has the required object on memory, and if not, it will get that model from the network. All it needs for that are a couple of sources from the types CachedObservableSource and MemoryCacheSource. It all makes more sense in an interaction diagram:

Everything on the right of the VM is repo´s responsibility. And Reportoire already provides the whole interface to achieve that. The only step left for the developer is to extend the CachedObservableSource to define which API calls should be done to get the model. Something that looks like…
public class UserNetworkSource extends CachedObservableSource<User, String> {
// Members
private final UserApi mApi;
// Constructor
public UserNetworkSource(UserApi pUserApi) {
mApi: pUserApi;
}
@NotNull
@Override
public Observable<Result<User>> onCreateResultObservable(String pUserId) {
return mApi.getUser(pUserId)
.map((Func1<User, Result<User>>) Result.Success::new)
.onErrorReturn(Result.Error::new);
}
}In this example, we use the injected API to ask for the User object related to a given id. As you can see, declaring your own sources is pretty straight forward.
When it comes to using the different repositories inside the view models, we used our dependency injection mechanism. This means, that the VM must grab the repository it needs from the corresponding module doing something similar to this:
RepositoryDependencyConfigurator.getHotelDetailsRepository();Which would be in our custom implementation of the dependency management, or you could use an annotation-style like @Inject if you prefer to use [Dagger] (https://github.com/google/dagger), that’s up to you!
To make the use of this pattern easier and accessible to everyone we have developed a library and uploaded to JCenter. It is open source and you can jump right into the core-code to find out more information. Just follow this [link] (https://github.com/trivago/reportoire).
Happy coding!
Thanks for reading.

Follow us on