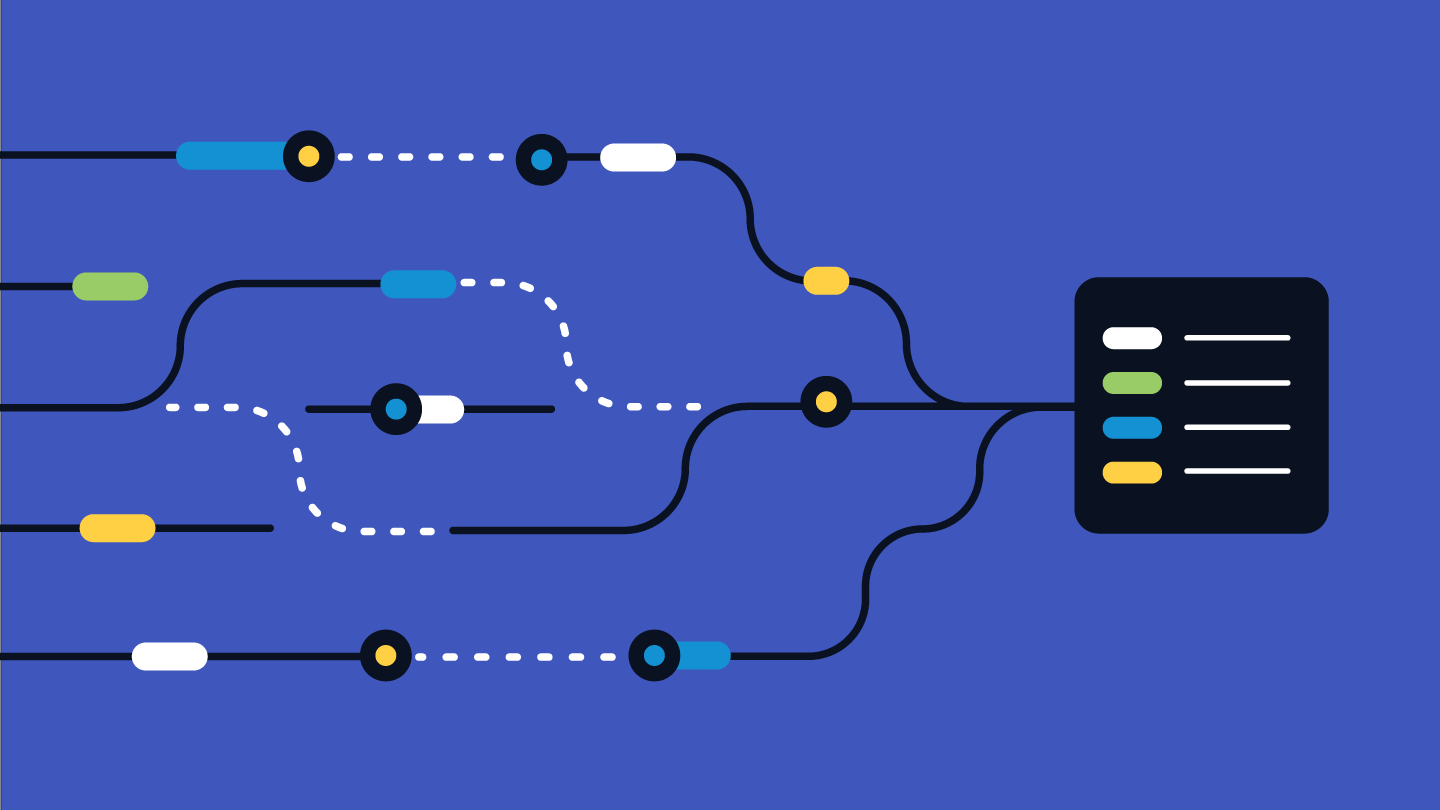
While working with data and analyzing the interactions of our users with the products we have today, it is essential to understand their behaviors by tracking their past actions, such as opening notifications, interacting with a blog, or creating a new login in the platform. In that context, the attribution study refers to the method of grouping together all of those actions in a specific pattern to generate one desired end result.









Follow us on