One of my favorite events throughout the year is the trivago tech get together. It's the one time where we all get together to celebrate tech. Here are some impressions from 2019:

One of my favorite events throughout the year is the trivago tech get together. It's the one time where we all get together to celebrate tech. Here are some impressions from 2019:
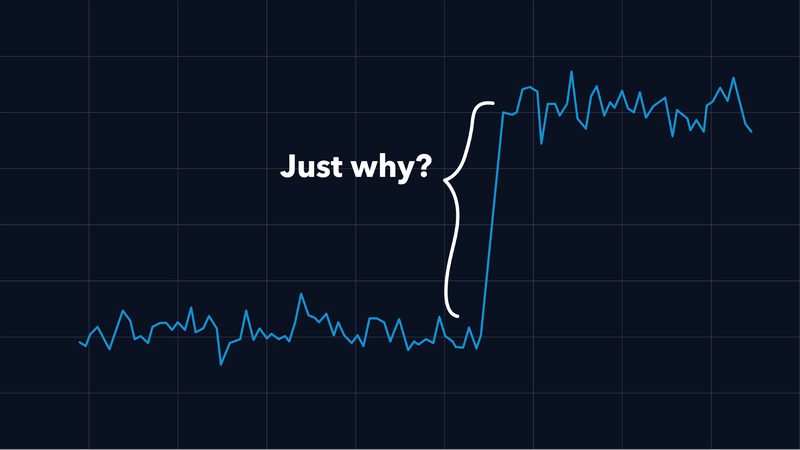
Metrics are one of the main building blocks in the topic of observability.
Hence, we have a lot of metrics within our applications and especially for the connections between our applications. Every outgoing request has its latency measured and we also record the sizes of the request and the response. These numbers are collected in histograms and based on that data, in our Grafana graphs, we create corresponding graphs that show us e.g. the median size of request- and response payloads or the 99th percentile of call durations.

At trivago we are working heavily on the web platform and, based on the scale that we need to serve our users, our applications need to cater for many different kinds of environments and conditions.

What does Data Science at trivago look like in practice? Which major challenges have we encountered as a travel-tech company since the COVID-19 outbreak? What's it like to work in Data Science at trivago? In this Q&A with James Neaves (Business Intelligence Lead), Andrea Fernandez (Data Science Team Lead), and Sheetij Jain (Product Manager in User Profiling) we'll answer all these questions and more.
This is part two of our series about trivago engineer's side projects. The first part is here.
As always, take a look and feel free to reach out to any of them if you'd like to exchange on any of their topics!
Fanatic learning is one of trivago's core values that forms a fundamental part of our engineering culture. It's very valuable to have curious minds around you that connect the dots to come up with new ideas and love to exchange knowledge on various topics. Since many of our engineers are involved in their own initiatives and projects outside work, we decided to introduce you to some of these side projects. The goal is to recognize their achievements and share their knowledge with our broader tech community. Take a look and feel free to reach out to any of them if you'd like to exchange on any of their topics!

Over the past few months, I was given the opportunity to try out the life of a Product Owner (PO), alongside retaining my responsibilities as an engineer. The life of a PO has always intrigued me since I joined trivago 2 years ago, and I always found myself unofficially taking on roles that were traditionally done by them. Things like reaching out to stakeholders for collaboration, thinking about KPIs and impact, and general "aligning". Perhaps it's because I simply love the sound of my own voice, but I've always felt a particularly high level of gratification from contributing in meetings. "Aligning" is an overused word in the workplace, but it is the best to describe where I derive my professional gratification from, outside of building things with code.

In our new series, trivago Tech Check-in, we're introducing you to some of our tech talents from across the globe who help keep our metasearch engine running smoothly everyday. In this first edition, you'll meet Fabian Fritzsche, an engineering intern that works on the Microservice-System that feeds our GraphQL API with up-to-date hotel data.

At trivago we operate a hybrid infrastructure of both on-premise machines and clusters on Google Cloud. Over time, we came up with a set of deployment guidelines for running our workloads as more and more of them are migrating to Google Cloud. These are not strict rules, but rather suggestions to best serve each team's needs.

After 15 years as a game/application developer and trainer, Benjamin decided to make test automation his career. He's currently a Test Automation Engineer in trivago's core QA team. Benjamin is also the author and maintainer of two open source projects for Cucumber BDD parallel test execution and reporting. He is an occasional speaker at conferences on testing and automation.

The price of reliability is the pursuit of the utmost simplicity.
— C.A.R. Hoare, Turing Award lecture
Have you ever enthusiastically released a new, delightful version to production and then suddenly started hearing a concerning number of notification sounds? Gets your heart beating right? After all, you didn't really expect this to happen because it worked in the development environment.

On a normal day, we ingest a lot of data into our ELK clusters (~6TB across all of our data centers). This is mostly operational data (logs) from different components in our infrastructure. This data ranges from purely technical info (logs from our services) to data about which pages our users are loading (intersection between business and technical data).
Throughout my career, I’ve had times where I worked 100% remotely. Overall working remotely can have benefits and even make you more productive as an engineer. I would like to share 5 tips that have worked very well for me.

Last year, when visiting CloudNativeCon/KubeCon Europe in Barcelona (one of the biggest cloud-focused conferences in Europe), I noticed that there were some companies present in the exhibition space whose primary focus wasn't software development. I was surprised to see companies from finance to sportswear as Cloud Native Computing Foundation (CNCF) sponsors. There I discovered various CNCF membership types and learned about the End User Supporter membership.
Imagine you go to your hotel for check-in and they say that your dog is not allowed even though the website clearly states that it is!
trivago gets information about millions of accommodations from hundreds of partners and they keep on updating. There are many differences not just in the data format, but also in the data itself. There can be many discrepancies in the information and consolidating them can be a very complex process. But it's our responsibility to provide the most accurate information to the best of our knowledge.
trivago's latest tech articles and regular tech tips straight to your inbox!
Tackling hard problems is like going on an adventure. Solving a technical challenge feels like finding a hidden treasure. Want to go treasure hunting with us?
View all job openings
Follow us on